Le nouveau plan directeur pour la pratique analytique : Façonner l'avenir de la prise de décision
La compréhension des informations est une quête éternelle de l'homme. La technologie utilisée pour gérer les données évolue depuis que les hommes préhistoriques ont commencé à peindre sur les murs de leurs grottes. Aujourd'hui, la technologie évolue extrêmement rapidement alors que nous nous dirigeons vers un changement de paradigme dans la façon dont nous exploitons nos avancées pour analyser les données et soutenir la prise de décision.
L'évolution de la pratique de l'analyse des données
Le stockage et le transfert numériques des données ont évolué rapidement. Au cours des dernières décennies, la technologie a amélioré sa capacité à capturer, stocker et gérer des quantités de données de plus en plus importantes et de formes diverses.
BI et entrepôts de données
L'analyse de données moderne est apparue avec la création d'applications de veille économique et d'entrepôts de données. Dans cette phase d'évolution, les données étaient capturées et stockées dans une base de données relationnelle très structurée. La correspondance entre les tables de données était bien définie pour faciliter l'accès aux applications de veille économique. Le résultat était que les résultats de l'analyse de données étaient très descriptifs et diagnostiques. Sur la base de ces données, les chefs d'entreprise pouvaient voir et comprendre ce qui s'était passé dans leurs opérations par le passé.
Big Data, Open Source et Cloud
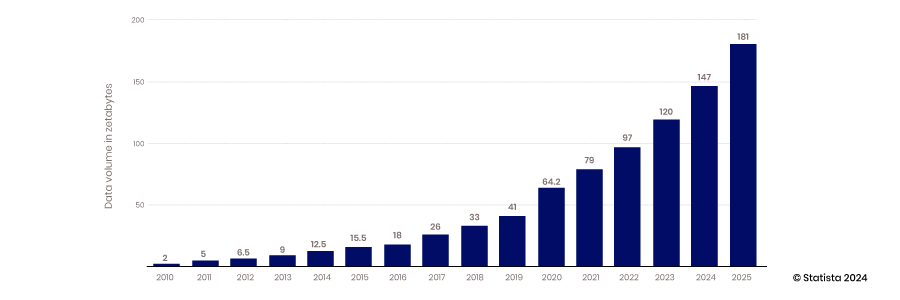
L'avènement de la capacité d'évolution du cloud, de la capacité des appareils mobiles et IoT à collecter des données et de la capacité des technologies open source à soutenir l'innovation ont marqué le début de l'ère du big data. Les entrepôts de données traditionnels et les bases de données structurées ne pouvaient pas évoluer pour répondre aux exigences d'hébergement des énormes volumes de données générées en permanence : de 2010 à 2017, la quantité de données produites par an est passée de 2 à 26 zettaoctets.
La plupart des données créées pendant cette période n'étaient pas structurées. Il était donc difficile de les stocker dans une base de données relationnelle structurée. Les lacs de données ont été créés pour résoudre ce problème en hébergeant ces données dans des fichiers plats. Aujourd'hui, 80 à 90 % des données des lacs de données ne sont pas structurées. Une fois toutes ces données stockées, le prochain défi consiste à y accéder et à les utiliser.
Pour résoudre ce problème, une communauté d’analystes et d’ingénieurs de données a émergé pour développer les compétences et les outils nécessaires à l’exploitation de la puissance des données. Cette évolution s’est traduite par des projets open source et par le renforcement des compétences autour de la transformation des données et de la création de techniques d’analyse plus sophistiquées. Cette tendance s’est également traduite par l’adoption des métadonnées pour favoriser un accès plus accessible aux données dans un monde moins organisé.
Avec l’accès à davantage de données et à de nouvelles compétences et outils, l’analyse est devenue plus prédictive et des modèles ont émergé, capables de fournir davantage d’informations sur les événements futurs.
Science des données et applications des données
Avec la croissance de la collecte de données et le développement des compétences en matière d’analyse de données, le marché s’est concentré sur la manière d’exploiter ces capacités pour obtenir des avantages concurrentiels. La combinaison des méthodes scientifiques avec les statistiques, le développement d’algorithmes et la connaissance des systèmes a conduit à l’émergence de la science des données. Cette capacité permet aux organisations d’exploiter leurs données non seulement pour créer des modèles prédictifs, mais également pour créer des systèmes qui prescrivent la meilleure alternative à toute décision. Cette avancée conduit à une plus grande automatisation et à des entreprises plus agiles et plus réactives.
La technologie de transfert et d'intégration des données ne suit pas le rythme
La collecte, le stockage et l'analyse des données ont considérablement évolué au fil des ans, mais l'accès aux données et leur intégration ont peu progressé. Des technologies et des approches comme l'ETL ont été développées avant le cloud, les technologies open source et l'IA.
La volonté d’appliquer les capacités des données, de l’analyse et de la science des données pour résoudre rapidement des problèmes commerciaux réels nécessite de repenser la manière d’accéder aux données de manière plus efficace. Les données sont désormais enfermées dans des lacs de données ou des applications métiers, et la technologie permettant de fusionner ces ensembles de données pour une analyse plus approfondie n’a pas suivi le rythme.
Obstacles techniques
La méthode standard d'intégration et d'accès aux données n'a pas changé depuis l'avènement de l'entrepôt de données et de la BI. SQL est la norme pour extraire des données des bases de données, et ETL est toujours le processus standard pour intégrer des données de différents systèmes. Pour accéder aux données de cette manière, les utilisateurs doivent écrire des scripts SQL pour interroger les données, savoir comment les données sont organisées et comprendre le fonctionnement de la technologie de base de données. Pour fusionner des ensembles de données, des processus sophistiqués doivent être créés pour extraire les données d'un système, les transformer et les charger dans une autre base de données. Fondamentalement, ces processus n'ont pas changé.
Obstacles politiques
Pour surmonter les obstacles techniques à l'accès aux données, des défis politiques peuvent également se présenter. Ceux qui collectent et sont responsables des données peuvent en restreindre l'accès. S'ils les partagent, ces propriétaires de domaines doivent surveiller la manière dont elles sont utilisées. Les données sensibles sont particulièrement préoccupantes. Les données seront-elles stockées de manière appropriée si elles sont partagées ? Les données seront-elles traitées avec le respect qu'elles méritent ? Par exemple, les analystes qui ne comprennent pas les nuances des règles HIPAA violeront-ils les politiques qui mettent en danger l'entreprise et ses clients ?
En outre, les analystes des différents services comprendront-ils la signification des données qui leur sont communiquées ? Analyseront-ils les données dans le contexte approprié ? Ce sont toutes des préoccupations légitimes qui limitent le partage dans le contexte actuel.
Travailler depuis des décennies avec des technologies héritées a également défini un état d’esprit qui limite l’accès plus efficace aux données, c’est-à-dire un état d’esprit axé sur les projets. Les technologies et pratiques existantes ont obligé les équipes de données à créer de nouveaux pipelines pour chaque demande de données. Cette approche réactive ne prend pas en compte les économies d’échelle permises par la construction de pipelines plus polyvalents qui peuvent être utilisés et réutilisés.
Redéfinition de la pratique de l'analyse
L’industrie entre dans une nouvelle phase de développement dominée par l’automatisation, l’apprentissage automatique (ML) et l’intelligence artificielle (IA). Le rythme de prise de décision s’accélère et la qualité des modèles d’IA sera un facteur de différenciation clé sur le marché. Les data scientists doivent pouvoir accéder rapidement à davantage de données de haute qualité pour améliorer la précision des modèles. Les managers doivent également avoir accès à des données contextuelles riches et de haute qualité pour suivre le rythme des décisions prises par l’automatisation et relever les défis trop complexes pour l’IA.
La prise de décision basée sur les données devient une condition préalable à la réussite sur des marchés concurrentiels, et les compétences en ingénierie des données nécessaires pour aider les analystes sont rares. L’IA est devenue courante et des applications à fort impact telles que la reconnaissance faciale et ChatGPT gagnent déjà du terrain. Ces applications ne sont que la pointe de l’iceberg, alors que les innovateurs s’efforcent d’intégrer l’IA dans l’automatisation et les processus commerciaux.
Les implications de l’IA sont vastes et importantes, mais la fiabilité de ces modèles reste douteuse. La surveillance de l’IA et de l’automatisation, tout en garantissant l’accès à des données de haute qualité, sera un facteur clé de différenciation pour accroître l’efficacité. Ceux qui ne peuvent pas s’adapter rapidement seront laissés pour compte.
Les entreprises doivent adopter une nouvelle approche d’analyse des données pour réussir dans cet environnement dynamique. Ce nouveau paradigme s’articule autour de quatre concepts :
- Contrôle décentralisé et fédération de données
- Mettre l'accent sur la collaboration et le partage
- Concentrez-vous sur les produits de données, et non sur les projets de données
- Adopter l’innovation et l’expérimentation
Contrôle de la décentralisation et fédération des données
Une technologie de requête puissante conçue pour un environnement cloud distribué est en train d'émerger. Une technologie open source comme Trino, développée par Facebook, sépare la fonction de calcul de la fonction de stockage afin que chacune puisse évoluer indépendamment. La technologie décompose également le processus de requête en étapes distinctes. Cette architecture exécute un morceau de code appelé coordinateur pour gérer plusieurs programmes de travail qui exécutent les processus d'interrogation de chaque base de données distincte. Cette technologie permet à une seule requête d'extraire des données de différentes sources simultanément. Elle permet également un traitement parallèle afin que de grands ensembles de données puissent être consultés beaucoup plus rapidement.
Les données étant stockées dans plusieurs bases de données et accessibles via une seule requête SQL fédérée, leur analyse devient beaucoup plus simple et plus rapide. Les ingénieurs informatiques et de données n'ont pas besoin de créer des pipelines ETL complexes pour déplacer les données d'une base de données source vers une base de données cible, qui doit être fusionnée et transformée avant de pouvoir être préparée pour l'analyse. Les données restent également au même endroit, ce qui réduit la quantité de données répliquées stockées dans les parcs informatiques et réduit les coûts de stockage et les erreurs. Ne consolidez pas les données et n'ajoutez pas de gouvernance ; laissez les données là où elles se trouvent et centralisez la gouvernance, les métadonnées et la découvrabilité.
Métadonnées consolidées
Si les requêtes de données fédérées sont très efficaces pour obtenir des données, elles ne le sont pas autant pour les trouver. Elles ont besoin d'une carte ou d'un index pour réduire le temps nécessaire à la localisation des données appropriées. Ce défi conduit à la création de mécanismes de découverte innovants. Les stratégies de gestion des métadonnées permettent aux requêtes fédérées de fonctionner beaucoup plus efficacement. En consolidant les métadonnées dans un emplacement central, les moteurs de requêtes fédérées peuvent rapidement déterminer où trouver les données sans analyser chacune de vos bases de données disparates pour chaque requête.
Les métadonnées consolidées peuvent être organisées dans des catalogues de données et les connexions entre différents ensembles de données peuvent être cartographiées à l'aide de graphes de connaissances. L'indexation des métadonnées réduit considérablement le temps d'exécution d'une requête fédérée.
Gouvernance décentralisée
Les logiciels open source sont certes très utiles, mais ils ne sont généralement pas adaptés aux entreprises. Pour que les entreprises soient sûres que leurs données sont sécurisées et que les décideurs soient sûrs que leurs données sont exactes et complètes, une gouvernance appropriée est nécessaire.
Avant la mise en œuvre des stratégies de fédération de données, lorsque les données étaient centralisées et accessibles via des pipelines de données ETL, le service informatique devait intégrer la sécurité et la gouvernance dans chaque pipeline. Avec la disparition de ces obstacles techniques, de nouvelles approches de gouvernance sont possibles.
Une couche de fédération prise en charge par un logiciel open source comme Trino permet un contrôle accru là où la gouvernance peut être mise en œuvre plus efficacement. L'accès n'a pas besoin d'être contrôlé et géré au niveau de chaque système source individuel, mais plutôt au niveau d'une couche centralisée. Avec des métadonnées détaillées centralisées, l'accès et la qualité des données peuvent être gérés à partir d'une plate-forme centrale plutôt qu'au niveau de la source de données. Cette configuration permet de gagner en efficacité et d'obtenir des contrôles d'accès plus précis. La centralisation des données via ETL entraîne une perte de contexte et le suivi de la lignée devient plus difficile. L'accès direct aux systèmes sources rend la lignée des données beaucoup plus simple.
Collaboration et partage
La nouvelle évolution de l'architecture d'analyse des données facilite le partage et la collaboration. Grâce à la centralisation des métadonnées, la compréhension des données et de leur contexte devient plus simple, ce qui simplifie considérablement le partage sécurisé des données entre les domaines. L'accès peut être défini au niveau des données plutôt qu'au niveau de la technologie. Les ingénieurs de données n'ont pas besoin de déterminer qui a accès à quel système source et d'intégrer cette politique dans leur pipeline. Les métadonnées étant extraites des données sources, l'accès peut être défini au niveau de la table de données, ce qui permet un partage des données beaucoup plus efficace.
Avec le partage des données, l’analyse des données devient un sport d’équipe. La maîtrise des données se développe et les connaissances en science des données deviennent une compétence essentielle de tout décideur. Les data scientists sont devenus moins divins, car une plus grande partie de leurs tâches peuvent être effectuées par des collègues plus compétents en données. Tous les employés ne sont pas des data scientists, mais la compréhension des concepts de la science des données devient une compétence essentielle.
Produits de données et projets de données
Le regroupement des données dans des produits de données réutilisables offre de nouvelles opportunités dans ce nouveau paradigme. Grâce aux outils permettant d'accéder aux données et de les gérer disponibles en un seul endroit, la création de produits de données réutilisables peut être rationalisée. Une fois que nous aurons une meilleure compréhension de nos données grâce à une gestion consolidée des métadonnées, la création de projets ponctuels de pipeline de données impliquant la recherche de données, leur compréhension et l'application de la gouvernance de manière indépendante n'est plus la seule option. Nous pouvons commencer à considérer les données comme un produit empaqueté avec une gouvernance et conçu pour être plus flexible et réutilisable. Les produits de données sont créés avec des données intégrées, nettoyées, normalisées et augmentées pour fournir l'ensemble de données de la plus haute valeur.
Grâce à un contrôle d'accès plus précis, davantage d'utilisateurs peuvent accéder aux produits de données. Cette approche constitue un changement significatif par rapport au projet de données personnalisé monolithique et inflexible, où l'accès doit être défini au niveau du système source. Le packaging des produits de données et leur publication sur une place de marché les rendent plus accessibles et en libre-service.
Le passage aux produits de données rend également l'analyse des données plus proactive plutôt que réactive. Au lieu de répondre aux demandes de données, les gestionnaires peuvent anticiper les produits de données qui pourraient être nécessaires. Ce changement rend l'expérience en gestion de produits précieuse. Un état d'esprit qui prend en compte les besoins futurs des consommateurs de données et la meilleure façon de fournir de la valeur est une caractéristique qui soutiendra les stratégies de produits de données réussies.
Expérimentation et innovation
Le nouveau paradigme de l'analyse des données va favoriser l'innovation et l'expérimentation. Grâce aux métadonnées centralisées prenant en charge les catalogues de données mondiaux qui indexent les données de votre parc informatique, la découverte de nouvelles données devient beaucoup plus simple. Les analystes, les ingénieurs et les responsables de produits de données peuvent explorer de nouvelles sources de données pour améliorer leurs analyses ou leurs produits de données. Grâce aux produits de données mis à disposition sur une place de marché, les décideurs et les data scientists peuvent accéder aux ensembles de données en quelques clics de souris. Le groupe Eckerson , groupe de conseil et de recherche en analyse de données, prédit que chaque grande organisation disposera d'une place de marché de produits de données d'ici trois à cinq ans.
La découverte de nouvelles sources et de nouveaux ensembles de données est la clé d'une plus grande expérimentation et innovation. Les catalogues de données consolidés et les marchés de produits de données facilitent grandement la découverte.
Un nouveau paradigme à l’ère de l’IA
L’évolution de l’architecture des requêtes crée des opportunités pour exploiter l’IA pour une plus grande efficacité et une plus grande portée. Les données se démocratisent de plus en plus, car toute personne possédant des compétences SQL et l’autorité appropriée peut exploiter un moteur de requête fédéré pour extraire des données de n’importe où dans l’organisation avec un seul script. Cette capacité, combinée à l’IA, rend les données encore plus accessibles en libre-service. De grands modèles de langage peuvent être utilisés pour traduire le langage commercial courant en une requête SQL, éliminant ainsi le besoin de connaître SQL. Gen AI prend également en charge l’analyse augmentée, où les utilisateurs professionnels peuvent demander à un moteur d’IA d’effectuer une analyse pour eux. Demandez à un chatbot, et l’IA affichera les corrélations entre les ensembles de données ou identifiera les facteurs à l’origine des tendances. Cela permet un accès aux données en libre-service encore plus efficace pour les analystes et les décideurs non techniques.
Nouvelles capacités
À mesure que l’IA gagne en puissance et que les obstacles à l’accès aux données disparaissent, les informations obtenues par l’IA seront directement intégrées dans les flux de travail d’automatisation, résolvant directement les problèmes sans intervention humaine. Bien que cela semble utopique, cette réalité pourrait bien être là avant que nous ne nous en rendions compte. Les humains devront surveiller ces processus et revérifier les résultats de l’IA. La capacité non seulement à créer ces modèles, mais aussi à les surveiller, nécessitera un accès facile aux données par les humains et une compréhension du fonctionnement de ces modèles.
Pas encore partenaire Concierto ?
Take the leap from data to AI
