Il nuovo progetto per la pratica analitica: Plasmare il futuro del processo decisionale
La comprensione delle informazioni è un'eterna ricerca umana. La tecnologia utilizzata per gestire i dati si è evoluta da quando gli uomini preistorici hanno iniziato a dipingere sulle pareti delle loro caverne. Oggi, la tecnologia si sta evolvendo molto rapidamente mentre ci dirigiamo verso un cambiamento di paradigma nel modo in cui sfruttiamo i nostri progressi per analizzare i dati e supportare il processo decisionale.
L'evoluzione della pratica di analisi dei dati
L'archiviazione e il trasferimento digitale dei dati si sono evoluti rapidamente. Negli ultimi decenni, la tecnologia ha migliorato la sua capacità di catturare, archiviare e gestire quantità sempre più grandi e forme diverse di dati
BI e Data Warehouse
L'analisi dei dati moderna è emersa con la creazione di applicazioni di business intelligence e data warehouse. In questa fase di evoluzione, i dati venivano catturati e archiviati in un database relazionale molto strutturato. La mappatura tra tabelle di dati era ben definita per supportare un facile accesso alle applicazioni di business intelligence. Il risultato era che gli output dell'analisi dei dati erano molto descrittivi e diagnostici. Sulla base di questi dati, i responsabili aziendali potevano vedere e comprendere cosa era successo nelle loro operazioni in passato.
Big Data, Open Source e Cloud
L'avvento della capacità del cloud di scalare, la capacità dei dispositivi mobili e IoT di raccogliere dati e la capacità della tecnologia open source di supportare l'innovazione hanno inaugurato l'era dei big data. I tradizionali data warehouse e i database strutturati non potevano scalare per soddisfare i requisiti di alloggiamento delle enormi quantità di dati generate costantemente: dal 2010 al 2017, la quantità di dati prodotta all'anno è cresciuta da 2 zettabyte a 26.
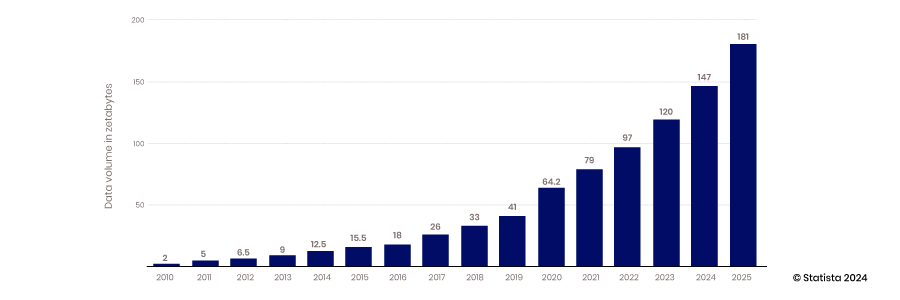
La maggior parte dei dati creati durante questo periodo non erano strutturati; pertanto, archiviarli in un database relazionale strutturato era difficile. I data lake sono stati creati per risolvere questo problema, ospitando questi dati in file piatti. Oggi, l'80-90% dei dati nei data lake non è strutturato. Con tutti questi dati archiviati, la sfida successiva è accedervi e utilizzarli.
Per affrontare questo problema, è emersa una comunità di analisti e ingegneri dei dati per sviluppare le competenze e gli strumenti necessari per sfruttare la potenza dei dati. Questo sviluppo ha incluso progetti open source e sviluppo di competenze sulla trasformazione dei dati e sulla creazione di tecniche di analisi più sofisticate. Questa tendenza ha incluso anche l'adozione di metadati per supportare un accesso più accessibile ai dati in un mondo meno organizzato.
Con l'accesso a più dati e a nuove competenze e strumenti, l'analisi è diventata più predittiva e sono emersi modelli in grado di fornire maggiori informazioni sugli eventi futuri.
Data Science e applicazioni dei dati
Con la crescita della raccolta dati e la creazione di competenze di analisi dati, il mercato ha spostato la sua attenzione su come sfruttare queste capacità per guidare vantaggi competitivi. La combinazione di metodi scientifici con statistiche, sviluppo di algoritmi e conoscenza dei sistemi ha portato all'emergere della scienza dei dati. Questa capacità consente alle organizzazioni di sfruttare i propri dati non solo per costruire modelli predittivi, ma anche per creare sistemi che prescrivono la migliore alternativa a qualsiasi decisione. Questo progresso porta a una maggiore automazione e le aziende diventano più agili e reattive.
La tecnologia di integrazione e spostamento dei dati non tiene il passo
La raccolta, l'archiviazione e l'analisi dei dati sono cambiate in modo significativo nel corso degli anni, ma l'accesso e l'integrazione dei dati hanno fatto pochi progressi. Tecnologie e approcci come ETL sono stati sviluppati prima del cloud, della tecnologia open source e dell'intelligenza artificiale.
La spinta ad applicare le capacità dei dati, dell'analisi e della scienza dei dati alla risoluzione rapida di problemi aziendali reali sta portando alla necessità di ripensare a come accedere ai dati in modo più efficiente. I dati sono rimasti bloccati in data lake o app aziendali e la tecnologia per unire questi set di dati per un'analisi più approfondita non ha tenuto il passo.
Barriere tecniche
Il modo standard per integrare e accedere ai dati non è cambiato dall'avvento del data warehouse e della BI. SQL è lo standard per estrarre i dati dai database, mentre ETL è ancora il processo standard per integrare i dati da sistemi diversi. Per accedere ai dati in questo modo, gli utenti devono scrivere script SQL per interrogare i dati, sapere come sono organizzati i dati e comprendere come funziona la tecnologia del database. Per unire i set di dati, devono essere creati processi sofisticati per estrarre i dati da un sistema, trasformarli e caricarli in un altro database. Fondamentalmente, questi processi non sono cambiati.
Barriere politiche
Nel superare le barriere tecniche all'accesso ai dati, anche le sfide politiche possono intralciare. Chi raccoglie e ha la responsabilità dei dati può limitare l'accesso. Se li condividono, questi proprietari di dominio devono monitorare come vengono utilizzati. I dati sensibili sono particolarmente preoccupanti. I dati saranno archiviati in modo appropriato se li condividono? I dati saranno gestiti con il rispetto che meritano? Ad esempio, gli analisti che non comprendono le sfumature delle regole HIPAA violeranno le policy che mettono a rischio l'azienda e i suoi clienti?
Inoltre, gli analisti dei vari dipartimenti capiranno il significato dei dati che vengono condivisi con loro? Analizzeranno i dati nel contesto appropriato? Sono tutte preoccupazioni legittime che limitano la condivisione nell'ambiente attuale.
Lavorare per decenni con la tecnologia legacy ha anche definito una mentalità che limita un accesso più efficiente ai dati, ovvero una mentalità focalizzata sul progetto. La tecnologia e le pratiche esistenti hanno costretto i team di dati a creare nuove pipeline per ogni richiesta di dati. Questo approccio reattivo non considera le economie di scala consentite dalla creazione di pipeline più versatili che possono essere utilizzate e riutilizzate.
Ridefinire la pratica analitica
Il settore sta entrando in una nuova fase di sviluppo dominata dall'automazione, dall'apprendimento automatico (ML) e dall'intelligenza artificiale (AI). Il ritmo del processo decisionale sta accelerando e la qualità dei modelli AI sarà un fattore di differenziazione chiave nel mercato. Gli scienziati dei dati hanno bisogno di un rapido accesso a dati di qualità più elevata per migliorare l'accuratezza del modello. I manager hanno anche bisogno di accedere a dati contestuali, ricchi e di qualità elevata per tenere il passo con il ritmo delle decisioni guidate dall'automazione e affrontare le sfide che sono troppo complesse per l'AI.
Il processo decisionale basato sui dati sta diventando un prerequisito per avere successo nei mercati competitivi e le competenze di data engineering necessarie per supportare gli analisti scarseggiano. L'intelligenza artificiale è diventata mainstream e applicazioni ad alto impatto come il riconoscimento facciale e ChatGPT stanno già guadagnando slancio. Queste applicazioni sono solo la punta dell'iceberg mentre gli innovatori lavorano per integrare l'intelligenza artificiale nell'automazione e nei processi aziendali.
Le implicazioni dell'IA sono diffuse e impattanti, ma l'affidabilità di questi modelli è ancora sospetta. Monitorare l'IA e l'automazione, assicurandosi al contempo che abbiano accesso a dati di alta qualità, sarà un fattore di differenziazione chiave nel guidare l'efficienza. Quelli che non riusciranno ad adattarsi rapidamente saranno lasciati indietro.
Le aziende devono adottare un nuovo approccio all'analisi dei dati per avere successo in questo ambiente dinamico. Questo nuovo paradigma è incentrato su quattro concetti:
- Controllo decentralizzato e federazione dei dati
- Concentrarsi sulla collaborazione e sulla condivisione
- Concentrarsi sui prodotti dati, non sui progetti dati
- Abbracciare l'innovazione e la sperimentazione
Controllo della decentralizzazione e federazione dei dati
Sta emergendo una potente tecnologia di query progettata per un ambiente cloud distribuito. La tecnologia open source come Trino, sviluppata da Facebook, separa la funzione di elaborazione dall'archiviazione in modo che ciascuna possa essere scalata in modo indipendente. La tecnologia suddivide inoltre il processo di query in fasi separate. Questa architettura esegue un pezzo di codice noto come coordinatore per gestire più programmi worker che eseguono i processi di query di ogni database separato. Questa tecnologia consente a una singola query di estrarre dati da varie fonti contemporaneamente. Consente inoltre l'elaborazione parallela in modo che grandi set di dati possano essere accessibili molto più rapidamente.
Con i dati archiviati in più database accessibili con una singola query SQL federata, l'analisi dei dati diventa molto più semplice e veloce. Gli ingegneri IT e dei dati non hanno bisogno di creare complesse pipeline ETL per spostare i dati da un database di origine a uno di destinazione, che devono essere uniti e trasformati prima di poter essere preparati per l'analisi. I dati rimangono anche in un unico posto, riducendo la quantità di dati replicati archiviati nelle proprietà IT e riducendo i costi di archiviazione e gli errori. Non consolidare i dati e aggiungere governance; lascia i dati dove sono e centralizza governance, metadati e rilevabilità.
Metadati consolidati
Sebbene le query di dati federate siano ottime per ottenere dati, non sono altrettanto efficaci nel trovarli. Hanno bisogno di una mappa o di un indice per ridurre il tempo necessario per individuare i dati appropriati. Questa sfida sta portando alla creazione di meccanismi di scoperta innovativi. Le strategie di gestione dei metadati stanno consentendo alle query federate di funzionare in modo molto più efficiente. Consolidando i metadati in un luogo centrale, i motori di query federati possono determinare rapidamente dove trovare i dati senza dover analizzare ciascuno dei tuoi database disparati per ogni query.
I metadati consolidati possono essere organizzati in cataloghi di dati e le connessioni tra diversi set di dati possono essere mappate utilizzando grafici di conoscenza. L'indicizzazione dei metadati riduce drasticamente il tempo necessario per l'esecuzione di una query federata.
Governance decentralizzata
Sebbene il software open source sia fantastico, in genere non è pronto per l'impresa. Affinché le organizzazioni siano sicure che i dati siano sicuri e i decisori si fidino che i loro dati siano accurati e completi, è necessaria una governance adeguata.
Prima dell'implementazione delle strategie di federazione dei dati, quando i dati erano centralizzati e accessibili tramite pipeline di dati ETL, l'IT doveva integrare sicurezza e governance in ogni pipeline. Con la caduta di queste barriere tecniche, sono possibili nuovi approcci alla governance.
Un livello di federazione supportato da software open source come Trino consente un maggiore controllo laddove la governance può essere implementata in modo più efficiente. L'accesso non deve essere controllato e gestito in ogni singolo sistema sorgente, ma piuttosto a un livello centralizzato. Con metadati dettagliati centralizzati, l'accesso e la qualità dei dati possono essere gestiti da una piattaforma centrale anziché dalla sorgente dati. Questa configurazione consente molte più efficienze e controlli di accesso granulari. La centralizzazione dei dati tramite ETL porta alla perdita di contesto e il tracciamento della discendenza diventa più difficile. L'accesso diretto ai sistemi sorgente rende la discendenza dei dati molto più semplice.
Collaborazione e condivisione
Il nuovo cambiamento nell'architettura dell'analisi dei dati consente una condivisione e una collaborazione più semplici. Con i metadati centralizzati, la comprensione dei dati e del loro contesto diventa più immediata, rendendo molto più semplice la condivisione sicura dei dati tra domini. L'accesso può essere definito a livello di dati anziché a livello di tecnologia. Gli ingegneri dei dati non devono stabilire chi ha accesso a quale sistema sorgente e creare tale policy nella loro pipeline. Con i metadati astratti dai dati sorgente, l'accesso può essere definito a livello di tabella dati, consentendo una condivisione dei dati molto più efficace.
Con la condivisione dei dati, l'analisi dei dati diventa uno sport di squadra. La data literacy cresce e la conoscenza della data science diventa un'abilità fondamentale per qualsiasi decisore. Gli scienziati dei dati sono diventati meno divini poiché ciò che fanno può essere gestito da colleghi più esperti di data science. Non tutti i dipendenti possono essere scienziati dei dati, ma comprendere i concetti della data science sta diventando un'abilità fondamentale.
Prodotti dati vs progetti dati
Il confezionamento dei dati in prodotti di dati riutilizzabili offre nuove opportunità in questo nuovo paradigma. Con gli strumenti per accedere e gestire i dati disponibili in un unico posto, la creazione di prodotti di dati riutilizzabili può essere semplificata. Una volta che abbiamo una migliore comprensione dei nostri dati attraverso la gestione consolidata dei metadati, la creazione di progetti di pipeline di dati una tantum che comportano la ricerca dei dati, la loro comprensione e l'applicazione della governance in modo indipendente non è più l'unica opzione. Possiamo iniziare a pensare ai dati come a un prodotto confezionato con la governance e progettato per essere più flessibile e riutilizzabile. I prodotti di dati sono creati con dati integrati, puliti, normalizzati e aumentati per fornire il set di dati di valore più elevato.
Con un controllo di accesso più granulare, più utenti possono accedere ai prodotti dati. Questo approccio è un cambiamento significativo rispetto al progetto dati personalizzato monolitico e inflessibile, in cui l'accesso deve essere definito a livello di sistema sorgente. Il confezionamento dei prodotti dati e la loro pubblicazione su un marketplace li rende più accessibili e self-service.
Il passaggio ai prodotti dati rende inoltre l'analisi dei dati più proattiva anziché reattiva. Invece di rispondere alle richieste di dati, i manager possono anticipare quali prodotti dati potrebbero essere richiesti. Questo passaggio rende preziosa l'esperienza nella gestione dei prodotti. Una mentalità che considera le esigenze future dei consumatori di dati e il modo migliore per fornire valore è una caratteristica che supporterà strategie di successo per i prodotti dati.
Sperimentazione e innovazione
Il nuovo paradigma di analisi dei dati introdurrà una maggiore innovazione e sperimentazione. Con metadati centralizzati che supportano cataloghi di dati globali che indicizzano i dati in tutto il tuo patrimonio IT, scoprire nuovi dati diventa molto più semplice. Analisti, ingegneri e responsabili dei prodotti dati possono esplorare nuove fonti di dati per migliorare le loro analisi o i loro prodotti dati. Con i prodotti dati resi disponibili in un mercato, i decisori e gli scienziati dei dati possono accedere a set di dati con pochi clic del mouse. Eckerson Group , gruppo di consulenza e ricerca di analisi dei dati, prevede che ogni grande organizzazione avrà un mercato di prodotti dati tra tre e cinque anni.
La rilevabilità di nuove fonti di dati e set di dati è la chiave per una maggiore sperimentazione e innovazione. I cataloghi di dati consolidati e i marketplace di prodotti di dati semplificano notevolmente la rilevabilità.
Nuovo paradigma nell'era dell'intelligenza artificiale
L'architettura di query in evoluzione crea opportunità per sfruttare l'intelligenza artificiale per una maggiore efficienza e portata. I dati stanno diventando più democratizzati poiché chiunque abbia competenze SQL e la giusta autorità può sfruttare un motore di query federato per estrarre dati da qualsiasi punto dell'organizzazione con un singolo script. Questa capacità, combinata con l'intelligenza artificiale, sta rendendo i dati ancora più self-service. I grandi modelli linguistici possono essere utilizzati per tradurre il linguaggio aziendale comune in una query SQL, eliminando la necessità di conoscere SQL. Gen AI supporta anche l'analisi aumentata, in cui gli utenti aziendali possono chiedere a un motore di intelligenza artificiale di condurre analisi per loro. Chiedi a un chatbot e l'intelligenza artificiale mostrerà correlazioni tra set di dati o identificherà i fattori che guidano le tendenze. Ciò consente un accesso ai dati self-service ancora più efficace da parte di analisti e decisori non tecnici.
Nuove capacità
Man mano che l'intelligenza artificiale diventa più potente e le barriere all'accesso ai dati si sciolgono, le intuizioni dell'intelligenza artificiale saranno immesse direttamente nel flusso di lavoro dell'automazione, risolvendo direttamente i problemi senza l'intervento umano. Sebbene ciò possa sembrare utopico, questa realtà potrebbe essere qui prima che ce ne rendiamo conto. Gli esseri umani dovranno monitorare questi processi e ricontrollare l'output dell'intelligenza artificiale. La capacità non solo di costruire questi modelli, ma anche di monitorarli, richiederà un facile accesso ai dati da parte degli esseri umani e una comprensione del funzionamento di questi modelli.
Richiedi una demo OGGI!
Take the leap from data to AI
