分析実践の新たな青写真: 意思決定の未来を形作る
情報を理解することは、人類の永遠の追求です。データ管理に使用されるテクノロジーは、先史時代の人類が洞窟の壁に絵を描き始めた頃から進化してきました。今日、テクノロジーは急速に進化しており、私たちは進歩を活用してデータを分析し、意思決定をサポートする方法においてパラダイムシフトに向かっています。
データ分析実践の進化
デジタルデータの保存と転送は急速に進化しています。過去数十年にわたり、テクノロジーはますます膨大で多様な形式のデータをキャプチャ、保存、管理する能力を進歩させてきました。
BI とデータ ウェアハウス
現代のデータ分析は、ビジネス インテリジェンス アプリケーションとデータ ウェアハウスの作成とともに登場しました。この進化の段階では、データは非常に構造化されたリレーショナル データベースにキャプチャされ、保存されました。データ テーブル間のマッピングは明確に定義されており、ビジネス インテリジェンス アプリケーションへの容易なアクセスをサポートします。その結果、データ分析の出力は非常に説明的で診断的なものになりました。このデータに基づいて、ビジネス マネージャーは過去の業務で何が起こったかを確認し、理解することができます。
ビッグデータ、オープンソース、クラウド
クラウドの拡張性、モバイルおよび IoT デバイスのデータ収集能力、オープンソース テクノロジーのイノベーション支援能力の出現により、ビッグ データの時代が到来しました。従来のデータ ウェアハウスや構造化データベースでは、絶えず生成される膨大な量のデータを格納する要件を満たすように拡張することができませんでした。2010 年から 2017 年にかけて、年間に生成されるデータ量は 2 ゼタバイトから 26 ゼタバイトに増加しました。
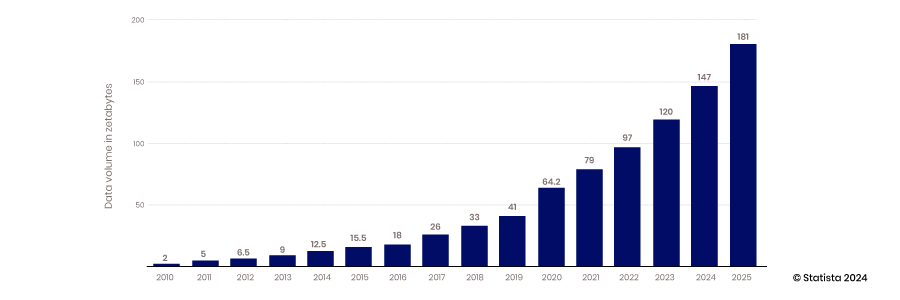
この期間に作成されたデータのほとんどは非構造化データであったため、構造化されたリレーショナル データベースに保存することは困難でした。この問題を解決するために、このデータをフラット ファイルに格納するデータ レイクが作成されました。現在、データ レイク内のデータの 80 ~ 90% は非構造化データです。このすべてのデータが保存されたら、次の課題はそれにアクセスして使用することです。
この問題に取り組むために、アナリストとデータ エンジニアのコミュニティが生まれ、データの力を活用するために必要なスキルとツールを構築しました。この開発には、オープン ソース プロジェクトや、データの変換とより高度な分析手法の作成に関するスキルの構築が含まれていました。この傾向には、あまり整理されていない世界でデータへのアクセスを容易にするためにメタデータを採用することも含まれていました。
より多くのデータと新しいスキルやツールにアクセスできるようになると、分析の予測精度が向上し、将来の出来事についてより多くの洞察を提供できるモデルが登場しました。
データサイエンスとデータアプリケーション
データ収集とデータ分析スキルの構築が進むにつれ、市場はこれらの機能を活用して競争上の優位性を高める方法に焦点を移しました。科学的手法と統計、アルゴリズム開発、システム知識を組み合わせることで、データ サイエンスが誕生しました。この機能により、組織はデータを活用して予測モデルを構築するだけでなく、あらゆる決定に対して最善の代替案を提示するシステムを作成することもできます。この進歩により、自動化が進み、企業はより機敏で応答性が向上します。
データ移動と統合の技術が追いついていない
データの収集、保存、分析は長年にわたって大きく変化してきましたが、データへのアクセスと統合はほとんど進歩していません。ETL などのテクノロジーとアプローチは、クラウド、オープンソース テクノロジー、AI よりも前に開発されました。
データ、分析、データ サイエンスの機能を適用して実際のビジネス上の問題を迅速に解決しようとする動きにより、データに効率よくアクセスする方法を再考する必要が生じています。データはデータ レイクやビジネス アプリに閉じ込められており、これらのデータ セットを統合してより詳細な分析を行うテクノロジが追いついていません。
技術的な障壁
データの統合とアクセスの標準的な方法は、データ ウェアハウスと BI の登場以来変わっていません。SQL はデータベースからデータを取得するための標準であり、ETL は依然としてさまざまなシステムからデータを統合するための標準プロセスです。この方法でデータにアクセスするには、ユーザーはデータをクエリするための SQL スクリプトを作成し、データがどのように整理されているかを把握し、データベース テクノロジの仕組みを理解する必要があります。データセットをマージするには、1 つのシステムからデータを抽出し、変換して別のデータベースにロードするための高度なプロセスを構築する必要があります。基本的に、これらのプロセスは変わっていません。
政治的障壁
データへのアクセスに対する技術的な障壁を克服する上で、政治的な課題も障害となることがあります。データを収集し、その責任を負う者は、アクセスを制限できます。データを共有する場合、これらのドメイン所有者は、データの使用方法を監視する必要があります。機密データは特に懸念されます。共有する場合、データは適切に保存されますか? データは、それにふさわしい敬意を持って取り扱われますか? たとえば、HIPAA 規則のニュアンスを理解していないアナリストは、会社とその顧客を危険にさらすポリシーに違反するでしょうか?
また、異なる部門のアナリストは、共有されたデータの意味を理解できるでしょうか? 適切なコンテキストでデータを分析できるでしょうか? これらはすべて、現在の環境で共有を制限する正当な懸念事項です。
数十年にわたってレガシー テクノロジーを使用してきたことで、データへのより効率的なアクセスを制限する考え方、つまりプロジェクト中心の考え方も確立されました。既存のテクノロジーとプラクティスにより、データ チームはデータ要求ごとに新しいパイプラインを作成する必要がありました。このリアクティブ アプローチでは、使用および再利用できるより汎用性の高いパイプラインを構築することで得られる規模の経済性が考慮されていません。
分析手法の再定義
業界は、自動化、機械学習 (ML)、人工知能 (AI) が主導する新しい開発段階に移行しています。意思決定のペースは加速しており、AI モデルの品質が市場での重要な差別化要因となります。データ サイエンティストは、モデルの精度を向上させるために、より高品質なデータに迅速にアクセスする必要があります。また、管理者は、自動化による意思決定のペースに遅れずについていき、AI では複雑すぎる課題に取り組むために、豊富で高品質なコンテキスト データにアクセスする必要があります。
データに基づく意思決定は、競争の激しい市場で成功するための前提条件になりつつあり、アナリストをサポートするために必要なデータ エンジニアリング スキルは不足しています。AI は主流となり、顔認識や ChatGPT などの影響力の大きいアプリケーションはすでに勢いを増しています。これらのアプリケーションは、イノベーターが AI を自動化やビジネス プロセスに統合する取り組みを進めている氷山の一角にすぎません。
AI の影響は広範囲に及び、大きな影響力を持っていますが、これらのモデルの信頼性は依然として疑わしいものです。AI と自動化を監視し、高品質なデータへのアクセスを確保することが、効率性を高める上で重要な差別化要因となります。迅速に適応できない企業は取り残されるでしょう。
企業がこのダイナミックな環境で成功するには、新しいデータ分析アプローチを採用する必要があります。この新しいパラダイムは、次の 4 つの概念を中心に据えています。
- 分散制御とデータ連携
- コラボレーションと共有に重点を置く
- データプロジェクトではなくデータ製品に焦点を当てる
- 革新と実験を受け入れる
分散制御とデータ連携
分散クラウド環境向けに設計された強力なクエリ テクノロジーが登場しています。Facebook で開発された Trino などのオープン ソース テクノロジーは、コンピューティング機能とストレージを分離し、それぞれを独立して拡張できるようにします。このテクノロジーは、クエリ プロセスを個別のステップに分割します。このアーキテクチャは、コーディネーターと呼ばれる 1 つのコードを実行して、各個別のデータベースをクエリするプロセスを実行する複数のワーカー プログラムを管理します。このテクノロジーにより、単一のクエリでさまざまなソースから同時にデータを取得できます。また、並列処理も可能になり、大規模なデータセットにはるかに迅速にアクセスできます。
複数のデータベースに保存されたデータに単一のフェデレーション SQL クエリでアクセスできるため、データ分析がはるかに簡単かつ迅速になります。IT エンジニアとデータ エンジニアは、ソース データベースからターゲット データベースにデータを移動するための複雑な ETL パイプラインを作成する必要がありません。分析用にデータを準備する前に、データをマージして変換する必要があります。また、データは 1 か所に保持されるため、IT 資産に保存される複製データの量が減り、ストレージ コストとエラーが削減されます。データを統合してガバナンスを追加するのではなく、データをそのままにして、ガバナンス、メタデータ、および検出可能性を一元化します。
統合メタデータ
フェデレーション データ クエリはデータを取得するのに優れていますが、データを検索するのはそれほど得意ではありません。適切なデータを見つけるのに必要な時間を短縮するには、マップまたはインデックスが必要です。この課題は、革新的な検出メカニズムの作成につながっています。メタデータ管理戦略により、フェデレーション クエリははるかに効率的に動作できます。メタデータを中央の場所に統合することで、フェデレーション クエリ エンジンは、クエリごとに異なるデータベースをそれぞれスキャンすることなく、データの場所をすばやく判断できます。
統合されたメタデータはデータ カタログに整理でき、異なるデータ セット間の接続はナレッジ グラフを使用してマッピングできます。メタデータをインデックス化すると、フェデレーション クエリの実行にかかる時間が大幅に短縮されます。
分散型ガバナンス
オープンソース ソフトウェアは優れていますが、通常はエンタープライズ対応ではありません。組織がデータの安全性を確信し、意思決定者がデータの正確性と完全性を信頼するには、適切なガバナンスが必要です。
データ フェデレーション戦略の実装前は、データが一元化され、ETL データ パイプラインによってアクセスされていたため、IT 部門は各パイプラインにセキュリティとガバナンスを組み込む必要がありました。これらの技術的な障壁がなくなると、ガバナンスに対する新しいアプローチが可能になります。
Trino のようなオープンソース ソフトウェアでサポートされているフェデレーション レイヤーにより、ガバナンスをより効率的に実装できる制御が強化されます。アクセスは、個々のソース システムで制御および管理する必要はなく、集中レイヤーで制御および管理する必要があります。詳細なメタデータが集中化されているため、データ ソースではなく中央プラットフォームからアクセスとデータ品質を管理できます。この構成により、効率性が大幅に向上し、きめ細かいアクセス制御が可能になります。ETL によるデータの集中化により、コンテキストが失われ、系統の追跡が難しくなります。ソース システムに直接アクセスすると、データ系統がはるかに簡単になります。
コラボレーションと共有
データ分析アーキテクチャの新しい変化により、共有とコラボレーションが容易になります。メタデータが一元化されているため、データとそのコンテキストをより簡単に理解できるようになり、ドメイン間でデータを安全に共有することがはるかに簡単になります。アクセスは、テクノロジー レベルではなくデータ レベルで定義できます。データ エンジニアは、誰がどのソース システムにアクセスできるかを決定し、そのポリシーをパイプラインに組み込む必要はありません。メタデータがソース データから抽象化されているため、アクセスをデータ テーブル レベルで定義でき、より効果的なデータ共有が可能になります。
データ共有により、データ分析はチームスポーツになります。データ リテラシーが向上し、データ サイエンスの知識はあらゆる意思決定者の中核スキルになります。データ サイエンティストの業務の多くは、データ リテラシーの高い同僚によって処理できるため、データ サイエンティストは神のような存在ではなくなりました。すべての従業員がデータ サイエンティストであるとは限りませんが、データ サイエンスの概念を理解することは中核スキルになりつつあります。
データ製品とデータプロジェクト
データを再利用可能なデータ製品にパッケージ化することで、この新しいパラダイムに新たな機会が生まれます。データにアクセスして管理するためのツールが 1 か所で利用できるため、再利用可能なデータ製品の構築を効率化できます。統合されたメタデータ管理によってデータをより深く理解できるようになると、データの検索、理解、ガバナンスの個別適用を伴う 1 回限りのデータ パイプライン プロジェクトを構築することが唯一の選択肢ではなくなります。データを、ガバナンスがパッケージ化され、より柔軟で再利用できるように設計された製品として考え始めることができます。データ製品は、統合、クリーン化、正規化、拡張されたデータを使用して構築され、最も価値の高いデータセットを提供します。
アクセス制御がより細かくなると、より多くのユーザーがデータ製品にアクセスできるようになります。このアプローチは、アクセスをソース システム レベルで定義する必要がある柔軟性のないモノリシックなカスタム データ プロジェクトからの大きな変化です。データ製品をパッケージ化してマーケットプレイスに公開すると、よりアクセスしやすく、セルフサービスになります。
データ製品への移行により、データ分析は受動的ではなく能動的になります。データ要求に応じるのではなく、管理者はどのようなデータ製品が必要になるかを予測できます。この移行により、製品管理の経験が価値あるものになります。データ消費者の将来のニーズを考慮し、価値を最も効果的に提供する方法を考える考え方は、データ製品戦略を成功させるのに役立つ特性です。
実験と革新
新しいデータ分析パラダイムは、より大きなイノベーションと実験をもたらします。IT 資産全体のデータをインデックスするグローバル データ カタログをサポートする一元化されたメタデータにより、新しいデータの発見がはるかに簡単になります。アナリスト、エンジニア、データ製品マネージャーは、新しいデータ ソースを探索して、分析やデータ製品を強化できます。データ製品がマーケットプレイスで利用可能になると、意思決定者やデータ サイエンティストはマウスを数回クリックするだけでデータ セットにアクセスできます。データ分析コンサルティングおよびリサーチ グループのEckerson グループは、 3 ~ 5 年以内にすべての大規模組織がデータ製品マーケットプレイスを持つようになると予測しています。
新しいデータ ソースとデータ セットの発見可能性は、より優れた実験とイノベーションの鍵となります。統合されたデータ カタログとデータ製品マーケットプレイスにより、発見可能性が大幅に向上します。
AI時代の新たなパラダイム
クエリ アーキテクチャの変化により、AI を活用して効率と範囲を向上させる機会が生まれます。SQL スキルと適切な権限を持つ人なら誰でもフェデレーション クエリ エンジンを活用して、単一のスクリプトで組織内のどこからでもデータを取得できるため、データはより民主化されています。この機能と AI を組み合わせることで、データのセルフサービス性がさらに高まります。大規模な言語モデルを使用して、一般的なビジネス言語を SQL クエリに変換できるため、SQL を知る必要がなくなります。Gen AI は拡張分析もサポートしており、ビジネス ユーザーは AI エンジンに分析の実行を依頼できます。チャットボットに依頼すると、AI がデータ セット間の相関関係を示したり、トレンドを推進する要因を特定したりします。これにより、非技術系のアナリストや意思決定者によるセルフサービス データ アクセスがさらに効果的になります。
新しい機能
AI がさらに強力になり、データへのアクセスの障壁がなくなると、AI の洞察が自動化ワークフローに直接取り込まれ、人間の介入なしに問題が直接解決されるようになります。これはユートピアのように聞こえますが、私たちが気付く前にこの現実が到来するかもしれません。人間はこれらのプロセスを監視し、AI の出力を再確認する必要があります。これらのモデルを構築するだけでなく監視する機能には、人間がデータに簡単にアクセスでき、これらのモデルがどのように機能するかを理解することが必要になります。
今すぐデモをリクエストしてください!
Take the leap from data to AI
