Rangka Tindakan Baharu untuk Amalan Analisis: Membentuk Masa Depan Pembuatan Keputusan
Memahami maklumat adalah usaha manusia yang berterusan. Teknologi yang digunakan untuk mengurus data telah berkembang sejak zaman prasejarah apabila manusia mula melukis di dinding gua mereka. Hari ini, kami menyaksikan anjakan paradigma iaitu kelajuan kemajuan teknologi mengubah cara kami menganalisis data dan menyokong pembuatan keputusan.
Evolusi Amalan Analisis Data
Storan digital dan pemindahan data telah berkembang pesat. Sepanjang dekad yang lalu, teknologi telah memajukan keupayaannya untuk mengambil, menyimpan dan mengurus jumlah yang semakin besar dan pelbagai bentuk data.
BI & Gudang Data
Analisis data moden muncul dengan penciptaan aplikasi risikan perniagaan dan gudang data. Dalam fasa evolusi ini, data telah ditangkap dan disimpan dalam pangkalan data hubungan yang sangat berstruktur. Pemetaan antara jadual data ditakrifkan dengan baik untuk menyokong akses mudah kepada aplikasi risikan perniagaan. Hasilnya ialah output analisis data adalah sangat deskriptif dan diagnostik. Berdasarkan data ini, pengurus perniagaan boleh memahami prestasi bersejarah, mengenal pasti corak dan isu asas.
Data Besar, Sumber Terbuka & Awan
Kemunculan keupayaan awan untuk menskala, keupayaan peranti mudah alih dan IoT untuk mengumpul data, dan keupayaan teknologi sumber terbuka untuk menyokong inovasi semuanya telah membawa kepada zaman data besar. Gudang data tradisional dan pangkalan data berstruktur tidak dapat berskala untuk memenuhi keperluan untuk menempatkan sejumlah besar data yang dijana secara berterusan – dari 2010 hingga 2017, pengeluaran data tahunan, meningkat daripada 2 hingga 26 zettabait.
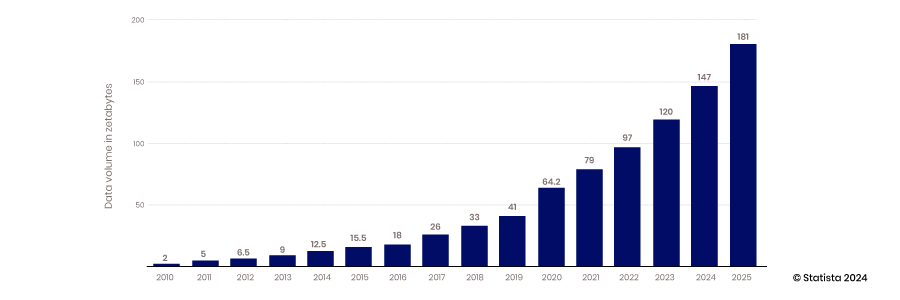
Kebanyakan data yang dibuat dalam tempoh ini adalah tidak berstruktur; oleh itu, menyimpannya dalam pangkalan data hubungan berstruktur adalah sukar. Lake Data dicipta untuk menyelesaikan masalah ini dengan menempatkan data ini dalam fail rata. Hari ini, 80-90% data dalam lake data tidak berstruktur. Dengan semua data ini disimpan, cabaran seterusnya ialah mengakses dan menggunakannya.
Untuk menangani masalah ini, kumpulan penganalisis dan jurutera data baharu telah muncul untuk membina kemahiran dan alatan yang diperlukan untuk memanfaatkan kuasa data tidak berstruktur. Ini termasuk projek sumber terbuka, membina kemahiran transformasi data dan mencipta teknik analisis yang lebih canggih. Merangkul pengurusan metadata untuk menyokong akses yang lebih mudah kepada data dalam dunia yang kurang teratur juga menjadi lebih penting.
Dengan akses kepada lebih banyak data, kemahiran baharu dan alatan inovatif, analisis menjadi lebih ramalan dan model muncul yang boleh memberikan lebih banyak cerapan tentang peristiwa masa hadapan.
Sains Data dan Aplikasi Data
Pertumbuhan pengumpulan data dan peningkatan tumpuan untuk membina kemahiran analisis data mendorong pasaran mengalihkan keutamaannya untuk mempelajari cara memanfaatkan keupayaan ini untuk memacu kelebihan daya saing baharu. Menggabungkan kaedah saintifik dengan statistik, pembangunan algoritma, dan pengetahuan sistem membawa kepada kemunculan sains data. Ini membolehkan organisasi memanfaatkan data mereka untuk bukan sahaja membina model ramalan tetapi juga untuk mencipta sistem yang menetapkan alternatif terbaik kepada sebarang keputusan. Kemajuan ini membawa kepada lebih banyak automasi dan syarikat menjadi lebih tangkas dan responsif.
Pergerakan Data dan Teknologi Integrasi tidak Mengikuti
Pengumpulan, penyimpanan dan analisis data telah berubah dengan ketara selama bertahun-tahun, tetapi mengakses dan menyepadukan data telah mencapai sedikit kemajuan. Teknologi dan pendekatan seperti ETL telah dibangunkan sebelum awan, teknologi sumber terbuka dan AI menjadi berleluasa.
Dorongan untuk menggunakan keupayaan data, analisis dan sains data untuk menyelesaikan masalah perniagaan sebenar dengan cepat mewujudkan keperluan untuk memikirkan semula cara mengakses data dengan lebih cekap. Data telah terkunci dalam lake data atau apl perniagaan, dan teknologi untuk menggabungkan set data ini untuk analisis yang lebih mendalam tidak dapat dikekalkan.
Halangan teknikal
Cara standard untuk menyepadukan dan mengakses data tidak berubah sejak kemunculan gudang data dan BI. SQL kekal sebagai standard untuk menyoal data daripada pangkalan data, dan ETL masih merupakan proses standard untuk menyepadukan data daripada sistem yang berbeza. Untuk mengakses data dengan cara ini, pengguna mesti menulis skrip SQL untuk menanyakan data, mengetahui cara data disusun dan memahami cara teknologi pangkalan data berfungsi. Untuk menggabungkan set data, proses yang canggih mesti dibina untuk mengekstrak data daripada satu sistem, mengubahnya dan memuatkannya ke pangkalan data yang lain. Pada asasnya, proses ini tidak berubah, ia terus kompleks dan memakan masa.
Halangan politik
Dalam mengatasi halangan teknikal untuk mengakses data, cabaran politik juga boleh menghalangnya. Mereka yang mengumpul dan bertanggungjawab untuk data boleh menyekat akses. Jika mereka berkongsinya, pemilik domain ini mesti memantau cara ia digunakan. Data sensitif amat membimbangkan. Adakah data akan disimpan dengan sewajarnya jika mereka berkongsinya? Adakah data akan diuruskan dengan penghormatan yang sewajarnya? Sebagai contoh, adakah penganalisis yang tidak memahami nuansa peraturan Akta Mudah Alih dan Akauntabiliti Insurans Kesihatan (HIPAA) akan melanggar dasar yang meletakkan syarikat dan pelanggannya berisiko?
Juga, adakah penganalisis di jabatan yang berbeza memahami maksud data yang dikongsi dengan mereka? Adakah mereka akan menganalisis data dalam konteks yang betul? Ini semua adalah kebimbangan sah yang mengehadkan perkongsian dalam persekitaran semasa.
Bekerja selama beberapa dekad dengan teknologi tradisional juga telah mentakrifkan minda warisan yang menyekat akses yang lebih cekap kepada data, dan memfokuskan projek. Teknologi dan amalan sedia ada telah memaksa pasukan data membuat saluran paip baharu untuk setiap permintaan data. Pendekatan reaktif ini tidak mengambil kira skala ekonomi yang disediakan dengan membina saluran paip yang lebih serba boleh yang boleh digunakan dan digunakan semula.
Mentakrifkan semula Amalan Analisis
Industri ini bergerak ke peringkat baharu pembangunan yang dikuasai oleh automasi, pembelajaran mesin (ML) dan kecerdasan buatan (AI). Kepantasan membuat keputusan semakin pantas, dan kualiti model AI akan menjadi pembeza utama dalam pasaran masa hadapan. Saintis data memerlukan akses pantas kepada data berkualiti tinggi untuk meningkatkan ketepatan model. Pengurus juga memerlukan akses kepada data kontekstual yang kaya untuk mengikuti kadar keputusan yang didorong oleh automasi dan menangani cabaran yang terlalu kompleks untuk AI.
Pembuatan keputusan berasaskan data menjadi penting untuk berjaya dalam pasaran yang kompetitif, namun terdapat kekurangan kemahiran kejuruteraan data yang diperlukan untuk menyokong penganalisis. AI telah menjadi arus perdana, dan aplikasi berimpak tinggi seperti pengecaman muka dan ChatGPT sudah mendapat momentum. Memandangkan inovator berusaha untuk mengintegrasikan AI ke dalam automasi dan proses perniagaan, aplikasi ini akan terbukti sebagai permulaan kepada trend yang telah lama berjalan.
Implikasi AI adalah meluas dan memberi kesan, tetapi kebolehpercayaan model ini masih diragui. Memantau AI dan automasi sambil memastikan mereka mempunyai akses kepada data terbaik, akan menjadi pembeza utama dalam kecekapan pemanduan. Mereka yang tidak dapat menyesuaikan diri dengan cepat akan ketinggalan.
Syarikat mesti menerima pendekatan analisis data baharu untuk berjaya dalam persekitaran dinamik ini. Paradigma baharu ini tertumpu kepada empat konsep:
- Kawalan terdesentralisasi dan persekutuan data
- Kerjasama dan Perkongsian
- Fokus pada produk data, bukan projek data
- Inovasi dan Eksperimen
Kawalan Desentralisasi & Persekutuan Data
Teknologi pertanyaan berkuasa yang direka bentuk untuk beroperasi dengan cekap dalam persekitaran awan teragih sedang muncul. Teknologi sumber terbuka seperti Trino, yang dibangunkan di Facebook, memisahkan fungsi pengkomputeran daripada storan supaya setiap satunya boleh membuat skala secara bebas. Teknologi ini juga memecahkan proses pertanyaan kepada langkah-langkah yang berasingan. Seni bina ini menjalankan satu kod yang dikenali sebagai penyelaras untuk mengurus berbilang program pekerja yang melaksanakan proses pertanyaan setiap pangkalan data berasingan. Teknologi ini membolehkan satu pertanyaan untuk menarik data daripada pelbagai sumber secara serentak. Ia juga membenarkan pemprosesan selari supaya set data yang besar boleh diakses dengan lebih cepat.
Dengan data yang disimpan dalam berbilang pangkalan data boleh diakses dengan pertanyaan SQL bersekutu tunggal, menganalisis data menjadi lebih mudah dan pantas. Jurutera IT dan data tidak perlu mencipta ETL pipeline yang kompleks untuk memindahkan data daripada sumber kepada pangkalan data sasaran, yang mesti digabungkan dan diubah sebelum ia boleh disediakan untuk analisis. Data itu juga kekal di satu tempat, mengurangkan jumlah data replika yang disimpan di estet IT dan mengurangkan kos penyimpanan dan ralat. Jangan satukan data dan tambah tadbir urus; biarkan data di tempatnya dan pusatkan tadbir urus, metadata dan aksebiliti.
Metadata Disatukan
Walaupun pertanyaan data bersekutu hebat untuk mendapatkan data, mereka tidak begitu mahir mencarinya. Mereka memerlukan peta atau indeks untuk memendekkan masa yang diperlukan untuk mencari data yang sesuai. Cabaran ini membawa kepada penciptaan mekanisme penemuan yang inovatif. Strategi pengurusan metadata membolehkan pertanyaan bersekutu beroperasi dengan lebih cekap. Dengan menyatukan metadata di tempat pusat, enjin pertanyaan bersekutu boleh dengan cepat menentukan tempat untuk mencari data tanpa mengimbas setiap pangkalan data anda yang berbeza untuk setiap pertanyaan.
Metadata disatukan boleh disusun dalam katalog data, dan sambungan antara set data yang berbeza boleh dipetakan menggunakan graf pengetahuan. Pengindeksan metadata secara drastik mengurangkan masa yang diperlukan pertanyaan bersekutu untuk dijalankan menjadikan data lebih mudah ditemui dan analisis lebih cekap.
Tadbir Urus Teragih
Walaupun perisian sumber terbuka hebat, ia biasanya tidak sedia untuk perusahaan. Untuk organisasi yakin bahawa data adalah selamat, dan pembuat keputusan mempercayai data mereka adalah tepat dan lengkap, tadbir urus yang betul diperlukan.
Sebelum pelaksanaan strategi persekutuan data, apabila data dipusatkan dan diakses oleh ETL data pipeline, IT perlu membina keselamatan dan tadbir urus ke dalam setiap saluran. Dengan halangan teknikal ini hilang, pendekatan baru untuk tadbir urus boleh dilakukan.
Lapisan persekutuan yang disokong oleh perisian sumber terbuka seperti Trino membolehkan lebih banyak kawalan di mana tadbir urus boleh dilaksanakan dengan lebih cekap. Akses tidak perlu dikawal dan diuruskan pada setiap sistem sumber individu, sebaliknya pada lapisan terpusat. Dengan metadata terperinci terpusat, akses dan kualiti data boleh diuruskan daripada platform pusat dan bukannya di sumber data. Konfigurasi ini membolehkan lebih banyak kecekapan dan kawalan akses berbutir. Memusatkan data melalui ETL membawa kepada kehilangan konteks, dan menjejaki keturunan menjadi lebih sukar. Akses terus kepada sistem sumber menjadikan garis keturunan data lebih mudah.
Kerjasama dan Perkongsian
Peralihan baharu dalam seni bina analisis data membolehkan perkongsian dan kerjasama lebih mudah. Dengan metadata terpusat, pemahaman data dan konteksnya menjadi lebih mudah, menjadikan perkongsian data yang selamat merentas domain lebih mudah. Akses boleh ditakrifkan pada peringkat data dan bukannya pada peringkat teknologi. Jurutera data tidak perlu menentukan siapa yang mempunyai akses kepada sistem sumber dan membina dasar itu ke dalam saluran mereka. Dengan metadata yang diabstraksikan daripada data sumber, akses boleh ditakrifkan pada peringkat jadual data, membolehkan perkongsian data yang lebih berkesan.
Dengan perkongsian data, analisis data menjadi sukan berpasukan. Celik data berkembang, dan pengetahuan sains data menjadi kemahiran teras mana-mana pembuat keputusan. Saintis data telah menjadi kurang tuhan kerana lebih banyak perkara yang mereka lakukan boleh diuruskan oleh lebih ramai rakan sekerja yang celik data. Tidak semua pekerja mungkin saintis data, tetapi memahami konsep sains data menjadi kemahiran teras.
Produk Data lwn Projek Data
Pembungkusan data ke dalam produk data boleh guna semula menawarkan peluang baharu dalam paradigma baharu ini. Dengan alatan untuk mengakses dan mentadbir data yang tersedia di satu tempat, membina produk data boleh guna semula boleh diperkemaskan. Sebaik sahaja kami mempunyai pemahaman yang lebih baik tentang data kami melalui pengurusan metadata yang disatukan, membina projek saluran data sekali sahaja yang memerlukan pencarian data, memahaminya dan menggunakan tadbir urus secara bebas bukan lagi satu-satunya pilihan. Kita boleh mula memikirkan data sebagai produk yang dibungkus dengan tadbir urus dan direka bentuk agar lebih fleksibel dan boleh digunakan semula. Produk data dibina dengan data bersepadu, dibersihkan, dinormalkan dan ditambah untuk menyampaikan set data nilai tertinggi.
Dengan kawalan akses yang lebih terperinci, lebih ramai pengguna boleh mengakses produk data. Pendekatan ini merupakan perubahan ketara daripada projek data tersuai monolitik yang tidak fleksibel, di mana akses mesti ditakrifkan pada peringkat sistem sumber. Membungkus produk data dan menerbitkannya ke pasaran menjadikan produk tersebut lebih mudah diakses dan layan diri.
Beralih kepada produk data juga menjadikan analisis data lebih proaktif dan bukannya reaktif. Daripada bertindak balas kepada permintaan data, pengurus boleh menjangkakan produk data yang mungkin diperlukan. Peralihan ini menjadikan pengalaman dalam pengurusan produk berharga. Pemikiran yang mempertimbangkan keperluan masa depan pengguna data dan cara terbaik untuk menyampaikan nilai ialah sifat yang akan menyokong strategi produk data yang berjaya.
Eksperimen dan Inovasi
Paradigma analisis data baharu akan membawa kepada inovasi dan percubaan yang lebih besar. Dengan metadata terpusat yang menyokong katalog data global yang mengindeks data merentas estet IT anda, penemuan data baharu menjadi lebih mudah. Penganalisis, jurutera dan pengurus produk data boleh meneroka sumber data baharu untuk meningkatkan analisis atau produk data mereka. Dengan produk data yang disediakan di pasaran, pembuat keputusan dan saintis data boleh mengakses set data dengan hanya beberapa klik tetikus. Kumpulan Eckerson - perundingan analisis data, dan kumpulan penyelidikan meramalkan bahawa setiap organisasi besar akan mempunyai pasaran produk data dalam masa tiga hingga lima tahun.
Aksebiliti sumber data dan set data baharu adalah kunci kepada percubaan dan inovasi yang lebih hebat. Katalog data yang disatukan dan pasaran produk data menjadikan aksebiliti lebih mudah.
Paradigma Baharu di Zaman AI
Seni bina pertanyaan yang berkembang mencipta peluang untuk memanfaatkan AI untuk kecekapan dan jangkauan yang lebih besar. Data menjadi lebih didemokrasikan kerana sesiapa sahaja yang mempunyai kemahiran SQL dan kuasa yang betul boleh memanfaatkan enjin pertanyaan bersekutu untuk menarik data dari mana-mana dalam organisasi dengan satu skrip. Keupayaan ini, digabungkan dengan AI, menjadikan data lebih layan diri. Model bahasa yang besar boleh digunakan untuk menterjemah bahasa perniagaan biasa ke dalam pertanyaan SQL, menghapuskan keperluan untuk mengetahui SQL. Gen AI juga menyokong analisis tambahan, di mana pengguna perniagaan boleh meminta enjin AI untuk menjalankan analisis untuk mereka. Tanya bot sembang, dan AI akan menunjukkan korelasi antara set data atau mengenal pasti faktor yang mendorong trend. Ini membolehkan capaian data layan diri yang lebih berkesan oleh penganalisis dan pembuat keputusan bukan teknikal.
Keupayaan baru
Apabila AI semakin berkuasa dan halangan kepada akses data semakin berkurangan, cerapan AI akan disalurkan terus ke dalam aliran kerja automasi, menyelesaikan masalah secara langsung tanpa campur tangan manusia. Walaupun ini kedengaran seperti angan-angan, realiti ini mungkin sudah wujud sebelum kita menyedarinya. Manusia perlu memantau proses ini dan menyemak semula output AI. Keupayaan untuk bukan sahaja membina model ini tetapi juga memantaunya memerlukan akses mudah kepada data oleh manusia dan pemahaman tentang cara model ini berfungsi.
Minta Demo HARI INI!
Take the leap from data to AI
