The New Blueprint for Analytics Practice: Shaping the Future of Decision-Making
Understanding information is an eternal human pursuit. The technology used to manage data has been evolving since prehistoric humans began painting on the walls of their caves. Today, we are witnessing a paradigm shift where the speed of technological advancements is transforming how we analyze data and support decision-making.
The Evolution of Data Analytics Practice
Digital storage and transfer of data have been evolving rapidly. Over the past decades, technology has advanced its ability to capture, store, and manage increasingly vast amounts and diverse forms of data.
BI & Data Warehouses
Modern data analytics emerged with the creation of business intelligence applications and data warehouses. In this phase of evolution, data was captured and stored in a very structured relational database. Mapping between data tables was well-defined to support easy access to business intelligence applications. The result was that the outputs of data analytics were very descriptive and diagnostic. Based on this data, business managers could understand historic performance, identify underlying patterns and issues.
Big Data, Open Source & the Cloud
The advent of the cloud’s ability to scale, mobile and IoT devices’ ability to collect data, and open-source technology’s ability to support innovation has all ushered in the age of big data. Traditional data warehouses and structured databases could not scale to meet the requirements for housing the vast amounts of data being generated constantly – from 2010 to 2017, the annual data production, grew from 2 to 26 zettabytes.
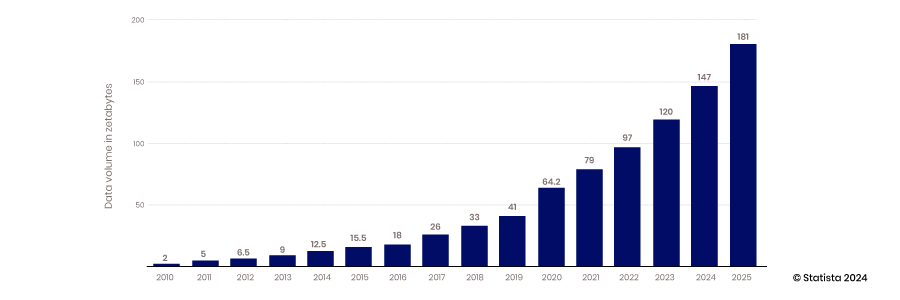
Most of the data created during this period was unstructured; therefore, storing it in a structured relational database was difficult. Data lakes were created to solve this problem by housing this data in flat files. Today, 80-90% of data in data lakes is unstructured. With all this data stored, the next challenge is accessing and using it.
To tackle this problem, a new breed of analysts and data engineers emerged to build the skills and tools required to harness the power of unstructured data. This included open-source projects, building data transformation skills, and creating more sophisticated analytics techniques. Embracing metadata management to support more accessible access to data in a less organized world also became more important.
With access to more data, new skills, and innovative tools, analysis became more predictive, and models emerged that could provide more insights into future events.
Data Science and Data Applications
The growth of data collection and increased focus on building data analysis skills drove the market to shift its priorities to learn how to leverage these capabilities to drive new competitive advantages. Combining scientific methods with statistics, algorithm development, and systems knowledge led to the emergence of data science. This enables organizations to leverage their data to not only build predictive models but also to create systems that prescribe the best alternative to any decision. This advancement leads to more automation and companies becoming more agile and responsive.
Data Movement and Integration Technology is not Keeping Up
Data collection, storage, and analysis have changed remarkably over the years, but accessing and integrating data has made little progress. Technologies and approaches such as ETL were developed before the cloud, open-source technology, and AI became prevalent.
The push to apply the capabilities of data, analytics, and data science to solve real business problems quickly is creating a need to rethink how to access data more efficiently. Data has become locked in data lakes or business apps, and the technology to merge these data sets for deeper analysis has not kept up.
Technical barriers
The standard way to integrate and access data has not changed since the advent of the data warehouse and BI. SQL remains the standard for querying data from databases, and ETL is still the standard process for integrating data from different systems. To access data this way, users must write SQL scripts to query data, know how the data is organized, and understand how the database technology works. To merge datasets, sophisticated processes must be built to extract data from one system, transform it, and load it into another database. Fundamentally, these processes have not changed they continue to be complex and time-consuming.
Political barriers
In overcoming the technical barriers to accessing data, political challenges can also get in the way. Those who collect and are responsible for data can restrict access. If they share it, these domain owners must monitor how it is used. Sensitive data is particularly concerning. Will data be stored appropriately if they share it? Will the data be managed with the respect it deserves? For example, will analysts who do not understand the nuances of Health Insurance Portability and Accountability Act (HIPAA) rules violate policies that put the company and its customers at risk?
Also, will analysts in different departments understand the meaning of the data that is shared with them? Will they analyze the data in the proper context? These are all legitimate concerns that limit sharing in the current environment.
Working for decades with traditional technology has also defined a legacy mindset that restricts more efficient access to data, and is, project-focused. Existing technology and practices have forced data teams to create new pipelines for each data request. This reactive approach does not consider the economies of scale provided by building more versatile pipelines that can be used and reused.
Redefining Analytics Practice
The industry is moving into a new stage of development dominated by automation, machine learning (ML), and artificial intelligence (AI). The pace of decision-making is accelerating, and the quality of AI models will be a key differentiator in the future marketplace. Data scientists need quick access to high-quality data to improve model accuracy. Managers also need access to rich, contextual data to keep up with the pace of automation-driven decisions and tackle the challenges that are too complex for AI.
Data-driven decision-making is becoming essential for succeeding in competitive markets, and yet there is a shortage of data engineering skills needed to support analysts. AI has gone mainstream, and high-impact applications such as facial recognition and ChatGPT are already gaining momentum. As innovators work to integrate AI into automation and business processes, these applications will prove to be just the beginning of a long-running trend.
The implications of AI are widespread and impactful, but the reliability of these models is still suspect. Monitoring AI and automation while ensuring they have access to the best data, will be a key differentiator in driving efficiency. Those that cannot adapt quickly will be left behind.
Companies must embrace a new data analytics approach to succeed in this dynamic environment. This new paradigm is centered around four concepts:
- Decentralized control and data federation
- Collaboration and Sharing
- Focus on data products, not data projects
- Innovation and Experimentation
Decentralization Control & Data Federation
Powerful query technology designed to operate efficiently in a distributed cloud environment is emerging. Open-source technology such as Trino, developed at Facebook, separates the computing function from storage so that each can scale independently. The technology also breaks down the query process into separate steps. This architecture runs one piece of code known as the coordinator to manage multiple worker programs that execute the processes of querying each separate database. This technology enables a single query to pull data from various sources simultaneously. It also allows parallel processing so that large datasets can be accessed much more quickly.
With data stored in multiple databases accessible with a single federated SQL query, analyzing data becomes much simpler and faster. IT and data engineers do not need to create complex ETL pipelines to move data from a source to a target database, which must be merged and transformed before it can be readied for analysis. The data also stays in one place, reducing the amount of replicated data stored in the IT estates and reducing storage costs and errors. Do not consolidate data and add governance; leave data where it is and centralize governance, metadata, and discoverability.
Consolidated Metadata
While federated data queries are great at getting data, they are not as good at finding it. They need a map or index to shorten the time required to locate the appropriate data. This challenge is leading to the creation of innovative discovery mechanisms. Metadata management strategies are enabling federated queries to operate much more efficiently. By consolidating metadata in a central place, federated query engines can quickly determine where to find data without scanning each of your disparate databases for every query.
Consolidated metadata can be organized in data catalogs, and connections between different data sets can be mapped using knowledge graphs. Indexing metadata drastically reduces the time it takes a federated query to run making data more discoverable and analysis more efficient.
Decentralized Governance
While open-source software is great, it typically is not enterprise-ready. For organizations to be confident that data is secure, and decision-makers trust their data is accurate and complete, proper governance is required.
Prior to the implementation of data federation strategies, when data was centralized and accessed by ETL data pipelines, IT had to build security and governance into each pipeline. With these technical barriers falling away, new approaches to governance are possible.
A federation layer supported by open-source software like Trino enables more control where governance can be implemented more efficiently. Access does not need to be controlled and managed at each individual source system, but rather at a centralized layer. With detailed metadata centralized, access and data quality can be managed from a central platform instead of at the data source. This configuration enables many more efficiencies and granular access controls. Centralizing data via ETL leads to lost context, and tracking lineage becomes more difficult. Direct access to source systems makes data lineage much more straightforward.
Collaboration and Sharing
The new shift in data analytics architecture enables easier sharing and collaboration. With metadata centralized, understanding data and its context becomes more straightforward, making safe sharing of data across domains much simpler. Access can be defined at the data level instead of at the technology level. Data engineers do not have to determine who has access to what source system and build that policy into their pipeline. With metadata abstracted away from the source data, access can be defined at the data table level, enabling much more effective data sharing.
With data sharing, data analysis becomes a team sport. Data literacy grows, and data science knowledge becomes a core skill of any decision-maker. Data scientists have become less godlike as more of what they do can be managed by more data-literate colleagues. Not all employees may be data scientists, but understanding data science concepts is becoming a core skill.
Data Products vs Data Projects
Packaging data into reusable data products offers new opportunities in this new paradigm. With the tools to access and govern data available in a single place, building reusable data products can be streamlined. Once we have a better understanding of our data through consolidated metadata management, building one-off data pipeline projects that entail searching for data, understanding it, and applying governance independently is no longer the only option. We can start thinking about data as a product packaged with governance and designed to be more flexible and reusable. Data products are built with integrated, cleaned, normalized, and augmented data to deliver the highest value dataset.
With more granular access control, more users can access data products. This approach is a significant change from the inflexible monolithic custom data project, where access must be defined at the source system level. Packaging data products and publishing them to a marketplace makes them more accessible and self-serve.
Shifting to data products also makes data analysis more proactive instead of reactive. Instead of responding to data requests, managers can anticipate what data products might be required. This shift makes experience in product management valuable. A mindset that considers the future needs of data consumers and how best to deliver value is a trait that will support successful data product strategies.
Experimentation and Innovation
The new data analytics paradigm will usher in greater innovation and experimentation. With centralized metadata supporting global data catalogs that index data across your IT estate, discovering new data becomes much simpler. Analysts, engineers, and data product managers can explore new data sources to enhance their analysis or data products. With data products made available in a marketplace, decision-makers and data scientists can access data sets with just a few clicks of the mouse. Eckerson group - data analytics consulting, and research group predicts that every large organization will have a data product marketplace in three to five years.
Discoverability of new data sources and data sets is the key to greater experimentation and innovation. Consolidated data catalogs and data product marketplaces make discoverability much easier.
New Paradigm in the Age of AI
The evolving query architecture creates opportunities to leverage AI for greater efficiency and reach. Data is becoming more democratized as anyone with some SQL skills and proper authority can leverage a federated query engine to pull data from anywhere in the organization with a single script. This capability, combined with AI, is making data even more self-serve. Large language models can be used to translate common business language into an SQL query, eliminating the need to know SQL. Gen AI also supports augmented analytics, where business users can ask an AI engine to conduct analysis for them. Ask a chatbot, and the AI will show correlations between data sets or identify factors driving trends. This enables even more effective self-serve data access by non-technical analysts and decision-makers.
New capabilities
As AI gets more powerful and barriers to data access diminish, AI insights will be fed directly into automation workflow, directly solving problems without human intervention. While this sounds utopian, this reality may be here before we realize it. Humans will have to monitor these processes and double-check AI output. The capability to not only build these models but also monitor them will require easy access to data by humans and an understanding of how these models work.
Request a Demo TODAY!
Take the leap from data to AI
