El nuevo plan para la práctica analítica: Dando forma al futuro de la toma de decisiones
Comprender la información es una búsqueda eterna del ser humano. La tecnología utilizada para gestionar los datos ha ido evolucionando desde que los seres humanos prehistóricos empezaron a pintar en las paredes de sus cuevas. Hoy en día, la tecnología está evolucionando con gran rapidez a medida que nos adentramos en un cambio de paradigma en la forma en que aprovechamos nuestros avances para analizar los datos y respaldar la toma de decisiones.
La evolución de la práctica del análisis de datos
El almacenamiento y la transferencia de datos digitales han evolucionado rápidamente. En las últimas décadas, la tecnología ha mejorado su capacidad para capturar, almacenar y gestionar cantidades cada vez mayores y formas diversas de datos.
Inteligencia empresarial y almacenes de datos
El análisis de datos moderno surgió con la creación de aplicaciones de inteligencia empresarial y almacenes de datos. En esta fase de la evolución, los datos se capturaban y almacenaban en una base de datos relacional muy estructurada. La correlación entre las tablas de datos estaba bien definida para facilitar el acceso a las aplicaciones de inteligencia empresarial. El resultado fue que los resultados del análisis de datos eran muy descriptivos y diagnósticos. Con base en estos datos, los gerentes de negocios podían ver y comprender lo que había sucedido en sus operaciones en el pasado.
Big Data, código abierto y la nube
La aparición de la capacidad de la nube para escalar, la capacidad de los dispositivos móviles y de la IoT para recopilar datos y la capacidad de la tecnología de código abierto para respaldar la innovación marcaron el comienzo de la era del big data. Los almacenes de datos tradicionales y las bases de datos estructuradas no podían escalar para satisfacer los requisitos de almacenamiento de las enormes cantidades de datos que se generan constantemente: de 2010 a 2017, la cantidad de datos producidos por año aumentó de 2 zettabytes a 26.
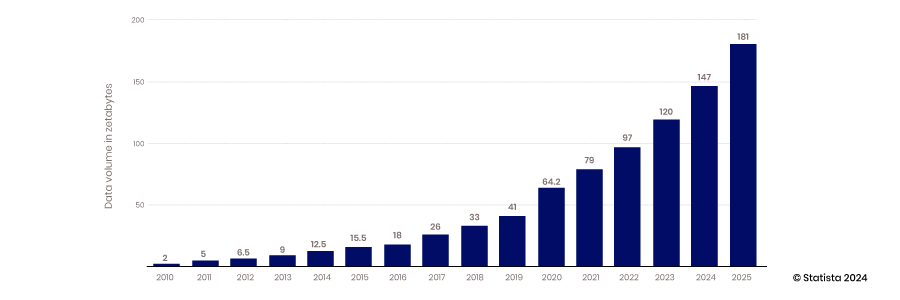
La mayor parte de los datos creados durante este período no estaban estructurados, por lo que almacenarlos en una base de datos relacional estructurada era difícil. Los lagos de datos se crearon para resolver este problema al alojar estos datos en archivos planos. Hoy en día, entre el 80 y el 90 % de los datos de los lagos de datos no están estructurados. Con todos estos datos almacenados, el siguiente desafío es acceder a ellos y utilizarlos.
Para abordar este problema, surgió una comunidad de analistas e ingenieros de datos que se encargaron de desarrollar las habilidades y herramientas necesarias para aprovechar el poder de los datos. Este desarrollo incluyó proyectos de código abierto y desarrollo de habilidades en torno a la transformación de datos y la creación de técnicas de análisis más sofisticadas. Esta tendencia también incluyó la adopción de metadatos para facilitar un acceso más accesible a los datos en un mundo menos organizado.
Con acceso a más datos y nuevas habilidades y herramientas, el análisis se volvió más predictivo y surgieron modelos que podían brindar más información sobre eventos futuros.
Ciencia de datos y aplicaciones de datos
Con el crecimiento de la recopilación de datos y el desarrollo de habilidades de análisis de datos, el mercado cambió su enfoque hacia cómo aprovechar estas capacidades para generar ventajas competitivas. La combinación de métodos científicos con estadísticas, desarrollo de algoritmos y conocimiento de sistemas condujo al surgimiento de la ciencia de datos. Esta capacidad permite a las organizaciones aprovechar sus datos no solo para construir modelos predictivos, sino también para crear sistemas que prescriben la mejor alternativa a cualquier decisión. Este avance conduce a una mayor automatización y a que las empresas se vuelvan más ágiles y receptivas.
La tecnología de movimiento e integración de datos no se mantiene al día
La recopilación, el almacenamiento y el análisis de datos han cambiado significativamente a lo largo de los años, pero el acceso a los datos y su integración han avanzado poco. Las tecnologías y los enfoques como ETL se desarrollaron antes de la nube, la tecnología de código abierto y la IA.
El afán por aplicar las capacidades de los datos, el análisis y la ciencia de datos para resolver rápidamente problemas empresariales reales está generando la necesidad de repensar cómo acceder a los datos de manera más eficiente. Los datos han quedado atrapados en lagos de datos o aplicaciones empresariales, y la tecnología para fusionar estos conjuntos de datos para realizar análisis más profundos no ha seguido el ritmo.
Barreras técnicas
La forma estándar de integrar y acceder a los datos no ha cambiado desde la aparición del almacén de datos y la inteligencia empresarial. SQL es el estándar para extraer datos de bases de datos, y ETL sigue siendo el proceso estándar para integrar datos de diferentes sistemas. Para acceder a los datos de esta manera, los usuarios deben escribir scripts SQL para consultar los datos, saber cómo se organizan los datos y comprender cómo funciona la tecnología de la base de datos. Para fusionar conjuntos de datos, se deben crear procesos sofisticados para extraer datos de un sistema, transformarlos y cargarlos en otra base de datos. Básicamente, estos procesos no han cambiado.
Barreras políticas
Para superar las barreras técnicas que impiden el acceso a los datos, también pueden surgir problemas políticos. Quienes recopilan y son responsables de los datos pueden restringir el acceso. Si los comparten, los propietarios de estos dominios deben supervisar cómo se utilizan. Los datos confidenciales son especialmente preocupantes. ¿Se almacenarán los datos de forma adecuada si se comparten? ¿Se manejarán los datos con el respeto que merecen? Por ejemplo, ¿los analistas que no comprenden los matices de las normas HIPAA violarán políticas que pongan en riesgo a la empresa y a sus clientes?
Además, ¿los analistas de los distintos departamentos comprenderán el significado de los datos que se comparten con ellos? ¿Analizarán los datos en el contexto adecuado? Todas estas son preocupaciones legítimas que limitan el intercambio en el entorno actual.
Trabajar durante décadas con tecnología heredada también ha definido una mentalidad que restringe el acceso más eficiente a los datos, es decir, una mentalidad centrada en los proyectos. La tecnología y las prácticas existentes han obligado a los equipos de datos a crear nuevos canales para cada solicitud de datos. Este enfoque reactivo no tiene en cuenta las economías de escala que se obtienen al construir canales más versátiles que se puedan usar y reutilizar.
Redefiniendo la práctica analítica
La industria está entrando en una nueva etapa de desarrollo dominada por la automatización, el aprendizaje automático (ML) y la inteligencia artificial (IA). El ritmo de la toma de decisiones se está acelerando y la calidad de los modelos de IA será un diferenciador clave en el mercado. Los científicos de datos necesitan un acceso rápido a más datos de alta calidad para mejorar la precisión de los modelos. Los gerentes también necesitan acceso a datos contextuales ricos y de alta calidad para mantenerse al día con el ritmo de las decisiones impulsadas por la automatización y abordar los desafíos que son demasiado complejos para la IA.
La toma de decisiones basada en datos se está convirtiendo en un requisito previo para tener éxito en los mercados competitivos, y las habilidades de ingeniería de datos necesarias para respaldar a los analistas son escasas. La IA se ha generalizado y las aplicaciones de alto impacto, como el reconocimiento facial y ChatGPT, ya están ganando impulso. Estas aplicaciones son solo la punta del iceberg a medida que los innovadores trabajan para integrar la IA en la automatización y los procesos comerciales.
Las implicaciones de la IA son generalizadas e impactantes, pero la fiabilidad de estos modelos aún es dudosa. Monitorear la IA y la automatización, al tiempo que se garantiza que tengan acceso a datos de alta calidad, será un diferenciador clave para impulsar la eficiencia. Aquellos que no puedan adaptarse rápidamente se quedarán atrás.
Las empresas deben adoptar un nuevo enfoque de análisis de datos para tener éxito en este entorno dinámico. Este nuevo paradigma se centra en cuatro conceptos:
- Control descentralizado y federación de datos
- Centrarse en la colaboración y el intercambio
- Centrarse en los productos de datos, no en los proyectos de datos
- Abrazando la innovación y la experimentación
Descentralización, control y federación de datos
Está surgiendo una potente tecnología de consulta diseñada para un entorno de nube distribuida. La tecnología de código abierto como Trino, desarrollada en Facebook, separa la función de computación de la de almacenamiento para que cada una pueda escalar de forma independiente. La tecnología también divide el proceso de consulta en pasos separados. Esta arquitectura ejecuta una pieza de código conocida como coordinador para administrar múltiples programas de trabajo que ejecutan los procesos de consulta de cada base de datos por separado. Esta tecnología permite que una sola consulta extraiga datos de varias fuentes simultáneamente. También permite el procesamiento en paralelo para que se pueda acceder a grandes conjuntos de datos mucho más rápidamente.
Con datos almacenados en múltiples bases de datos accesibles con una única consulta SQL federada, analizar los datos se vuelve mucho más simple y rápido. Los ingenieros de TI y de datos no necesitan crear complejos procesos ETL para mover datos desde una base de datos de origen a una de destino, que deben fusionarse y transformarse antes de que puedan prepararse para el análisis. Los datos también permanecen en un solo lugar, lo que reduce la cantidad de datos replicados almacenados en los activos de TI y reduce los costos de almacenamiento y los errores. No consolide los datos y agregue gobernanza; deje los datos donde están y centralice la gobernanza, los metadatos y la capacidad de descubrimiento.
Metadatos consolidados
Si bien las consultas de datos federados son excelentes para obtener datos, no son tan buenas para encontrarlos. Necesitan un mapa o índice para acortar el tiempo necesario para localizar los datos adecuados. Este desafío está llevando a la creación de mecanismos de descubrimiento innovadores. Las estrategias de gestión de metadatos están permitiendo que las consultas federadas funcionen de manera mucho más eficiente. Al consolidar los metadatos en un lugar central, los motores de consultas federadas pueden determinar rápidamente dónde encontrar los datos sin escanear cada una de las distintas bases de datos para cada consulta.
Los metadatos consolidados se pueden organizar en catálogos de datos y las conexiones entre diferentes conjuntos de datos se pueden mapear mediante gráficos de conocimiento. La indexación de metadatos reduce drásticamente el tiempo que tarda en ejecutarse una consulta federada.
Gobernanza descentralizada
Si bien el software de código abierto es excelente, por lo general no está preparado para las empresas. Para que las organizaciones tengan la seguridad de que los datos están protegidos y los responsables de la toma de decisiones confíen en que sus datos son precisos y completos, se requiere una gobernanza adecuada.
Antes de la implementación de las estrategias de federación de datos, cuando los datos se centralizaban y se accedía a ellos mediante canales de datos ETL, el departamento de TI tenía que incorporar seguridad y gobernanza en cada canal. Con la desaparición de estas barreras técnicas, son posibles nuevos enfoques de gobernanza.
Una capa de federación respaldada por software de código abierto como Trino permite un mayor control donde la gobernanza se puede implementar de manera más eficiente. El acceso no necesita ser controlado y administrado en cada sistema de origen individual, sino en una capa centralizada. Con metadatos detallados centralizados, el acceso y la calidad de los datos se pueden administrar desde una plataforma central en lugar de desde la fuente de datos. Esta configuración permite mucha más eficiencia y controles de acceso granulares. La centralización de datos a través de ETL conduce a la pérdida de contexto y el seguimiento del linaje se vuelve más difícil. El acceso directo a los sistemas de origen hace que el linaje de datos sea mucho más sencillo.
Colaboración y compartición
El nuevo cambio en la arquitectura de análisis de datos permite compartir y colaborar de forma más sencilla. Con metadatos centralizados, comprender los datos y su contexto se vuelve más sencillo, lo que hace que compartir datos de forma segura entre dominios sea mucho más sencillo. El acceso se puede definir a nivel de datos en lugar de a nivel de tecnología. Los ingenieros de datos no tienen que determinar quién tiene acceso a qué sistema de origen e incorporar esa política en su flujo de trabajo. Con metadatos abstraídos de los datos de origen, el acceso se puede definir a nivel de tabla de datos, lo que permite compartir datos de forma mucho más eficaz.
Con el intercambio de datos, el análisis de datos se convierte en un deporte de equipo. La alfabetización de datos crece y el conocimiento de la ciencia de datos se convierte en una habilidad fundamental para cualquier persona que toma decisiones. Los científicos de datos se han vuelto menos parecidos a dioses, ya que una mayor parte de lo que hacen puede ser manejada por colegas con más conocimientos de datos. Puede que no todos los empleados sean científicos de datos, pero comprender los conceptos de la ciencia de datos se está convirtiendo en una habilidad fundamental.
Productos de datos vs. proyectos de datos
El empaquetado de datos en productos de datos reutilizables ofrece nuevas oportunidades en este nuevo paradigma. Con las herramientas para acceder a los datos y administrarlos disponibles en un solo lugar, la creación de productos de datos reutilizables se puede agilizar. Una vez que tengamos una mejor comprensión de nuestros datos a través de la gestión consolidada de metadatos, la creación de proyectos de canalización de datos únicos que impliquen la búsqueda de datos, su comprensión y la aplicación de la gobernanza de forma independiente ya no es la única opción. Podemos empezar a pensar en los datos como un producto empaquetado con gobernanza y diseñado para ser más flexible y reutilizable. Los productos de datos se crean con datos integrados, depurados, normalizados y aumentados para ofrecer el conjunto de datos de mayor valor.
Con un control de acceso más granular, más usuarios pueden acceder a los productos de datos. Este enfoque es un cambio significativo con respecto al proyecto de datos personalizado, monolítico e inflexible, en el que el acceso debe definirse en el nivel del sistema de origen. Empaquetar los productos de datos y publicarlos en un mercado los hace más accesibles y autogestionados.
El cambio a productos de datos también hace que el análisis de datos sea más proactivo en lugar de reactivo. En lugar de responder a las solicitudes de datos, los gerentes pueden anticipar qué productos de datos podrían ser necesarios. Este cambio hace que la experiencia en la gestión de productos sea valiosa. Una mentalidad que tenga en cuenta las necesidades futuras de los consumidores de datos y la mejor manera de ofrecer valor es una característica que respaldará el éxito de las estrategias de productos de datos.
Experimentación e Innovación
El nuevo paradigma de análisis de datos traerá consigo una mayor innovación y experimentación. Con metadatos centralizados que respaldan catálogos de datos globales que indexan datos en todo su parque de TI, descubrir nuevos datos se vuelve mucho más sencillo. Los analistas, ingenieros y gerentes de productos de datos pueden explorar nuevas fuentes de datos para mejorar sus análisis o productos de datos. Con productos de datos disponibles en un mercado, los tomadores de decisiones y los científicos de datos pueden acceder a conjuntos de datos con solo unos pocos clics del mouse. Eckerson Group , un grupo de investigación y consultoría en análisis de datos, predice que todas las grandes organizaciones tendrán un mercado de productos de datos en tres a cinco años.
La capacidad de descubrir nuevas fuentes y conjuntos de datos es la clave para una mayor experimentación e innovación. Los catálogos de datos consolidados y los mercados de productos de datos facilitan enormemente la capacidad de descubrirlos.
Nuevo paradigma en la era de la IA
La cambiante arquitectura de consultas crea oportunidades para aprovechar la IA para lograr una mayor eficiencia y alcance. Los datos se están democratizando cada vez más, ya que cualquier persona con algunas habilidades de SQL y la autoridad adecuada puede aprovechar un motor de consultas federado para extraer datos de cualquier parte de la organización con un solo script. Esta capacidad, combinada con la IA, está haciendo que los datos sean aún más autoservicio. Se pueden usar modelos de lenguaje grandes para traducir el lenguaje comercial común a una consulta SQL, lo que elimina la necesidad de conocer SQL. Gen AI también admite análisis aumentados, donde los usuarios comerciales pueden pedirle a un motor de IA que realice análisis por ellos. Pregúntele a un chatbot y la IA mostrará correlaciones entre conjuntos de datos o identificará factores que impulsan las tendencias. Esto permite un acceso a los datos de autoservicio aún más efectivo por parte de analistas y tomadores de decisiones no técnicos.
Nuevas capacidades
A medida que la IA se vuelve más poderosa y las barreras para el acceso a los datos desaparecen, los conocimientos de IA se incorporarán directamente al flujo de trabajo de automatización, lo que permitirá resolver los problemas sin intervención humana. Aunque esto suene utópico, es posible que esta realidad llegue antes de que nos demos cuenta. Los humanos tendrán que supervisar estos procesos y comprobar dos veces los resultados de la IA. La capacidad no solo de crear estos modelos, sino también de supervisarlos, requerirá un fácil acceso a los datos por parte de los humanos y una comprensión de cómo funcionan estos modelos.
¡Solicite una demostración HOY!
Take the leap from data to AI
