O novo plano para a prática analítica: Moldando o futuro da tomada de decisões
Entender informações é uma eterna busca humana. A tecnologia usada para gerenciar dados vem evoluindo desde que os humanos pré-históricos começaram a pintar nas paredes de suas cavernas. Hoje, a tecnologia está evoluindo extremamente rápido, à medida que nos dirigimos para uma mudança de paradigma em como aproveitamos nossos avanços para analisar dados e dar suporte à tomada de decisões.
A evolução da prática de análise de dados
O armazenamento digital e a transferência de dados têm evoluído rapidamente. Nas últimas décadas, a tecnologia avançou sua capacidade de capturar, armazenar e gerenciar quantidades cada vez maiores e diversas formas de dados
BI e Armazéns de Dados
A análise de dados moderna surgiu com a criação de aplicativos de inteligência empresarial e data warehouses. Nessa fase de evolução, os dados eram capturados e armazenados em um banco de dados relacional muito estruturado. O mapeamento entre tabelas de dados era bem definido para dar suporte ao acesso fácil a aplicativos de inteligência empresarial. O resultado foi que as saídas da análise de dados eram muito descritivas e diagnósticas. Com base nesses dados, os gerentes de negócios podiam ver e entender o que havia acontecido em suas operações no passado.
Big Data, código aberto e a nuvem
O advento da capacidade da nuvem de escalar, a capacidade dos dispositivos móveis e IoT de coletar dados e a capacidade da tecnologia de código aberto de dar suporte à inovação inauguraram a era do big data. Os data warehouses tradicionais e os bancos de dados estruturados não conseguiam escalar para atender aos requisitos de abrigar as vastas quantidades de dados sendo geradas constantemente - de 2010 a 2017, a quantidade de dados produzidos por ano cresceu de 2 zettabytes para 26.
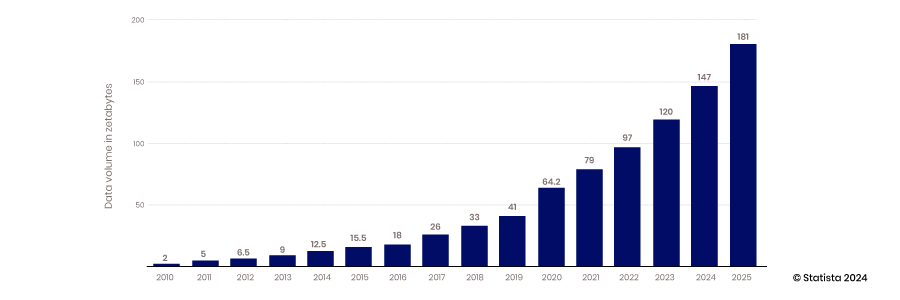
A maioria dos dados criados durante esse período não era estruturada; portanto, armazená-los em um banco de dados relacional estruturado era difícil. Data lakes foram criados para resolver esse problema, abrigando esses dados em arquivos simples. Hoje, 80-90% dos dados em data lakes não são estruturados. Com todos esses dados armazenados, o próximo desafio é acessá-los e usá-los.
Para lidar com esse problema, uma comunidade de analistas e engenheiros de dados surgiu para desenvolver as habilidades e ferramentas necessárias para aproveitar o poder dos dados. Esse desenvolvimento incluiu projetos de código aberto e desenvolvimento de habilidades em torno da transformação de dados e criação de técnicas analíticas mais sofisticadas. Essa tendência também incluiu a adoção de metadados para dar suporte a um acesso mais acessível aos dados em um mundo menos organizado.
Com acesso a mais dados e novas habilidades e ferramentas, a análise se tornou mais preditiva, e surgiram modelos que poderiam fornecer mais insights sobre eventos futuros.
Ciência de Dados e Aplicações de Dados
Com o crescimento da coleta de dados e a construção de habilidades de análise de dados, o mercado mudou seu foco para como alavancar essas capacidades para impulsionar vantagens competitivas. A combinação de métodos científicos com estatísticas, desenvolvimento de algoritmos e conhecimento de sistemas levou ao surgimento da ciência de dados. Essa capacidade permite que as organizações alavanquem seus dados não apenas para construir modelos preditivos, mas também para criar sistemas que prescrevem a melhor alternativa para qualquer decisão. Esse avanço leva a mais automação e as empresas se tornam mais ágeis e responsivas.
A tecnologia de integração e movimentação de dados não está acompanhando
A coleta, o armazenamento e a análise de dados mudaram significativamente ao longo dos anos, mas o acesso e a integração de dados fizeram pouco progresso. Tecnologias e abordagens como ETL foram desenvolvidas antes da nuvem, da tecnologia de código aberto e da IA.
O impulso para aplicar as capacidades de dados, análises e ciência de dados para resolver problemas reais de negócios rapidamente está trazendo uma necessidade de repensar como acessar dados de forma mais eficiente. Os dados ficaram presos em data lakes ou aplicativos de negócios, e a tecnologia para mesclar esses conjuntos de dados para análise mais profunda não acompanhou.
Barreiras técnicas
A maneira padrão de integrar e acessar dados não mudou desde o advento do data warehouse e do BI. SQL é o padrão para extrair dados de bancos de dados, e ETL ainda é o processo padrão para integrar dados de diferentes sistemas. Para acessar dados dessa maneira, os usuários devem escrever scripts SQL para consultar os dados, saber como os dados são organizados e entender como a tecnologia de banco de dados funciona. Para mesclar conjuntos de dados, processos sofisticados devem ser criados para extrair dados de um sistema, transformá-los e carregá-los em outro banco de dados. Fundamentalmente, esses processos não mudaram.
Barreiras políticas
Ao superar as barreiras técnicas para acessar dados, desafios políticos também podem atrapalhar. Aqueles que coletam e são responsáveis pelos dados podem restringir o acesso. Se eles os compartilharem, esses proprietários de domínio devem monitorar como eles são usados. Dados sensíveis são particularmente preocupantes. Os dados serão armazenados adequadamente se eles os compartilharem? Os dados serão tratados com o respeito que merecem? Por exemplo, analistas que não entendem as nuances das regras HIPAA violarão políticas que colocam a empresa e seus clientes em risco?
Além disso, os analistas em diferentes departamentos entenderão o significado dos dados que são compartilhados com eles? Eles analisarão os dados no contexto adequado? Todas essas são preocupações legítimas que limitam o compartilhamento no ambiente atual.
Trabalhar por décadas com tecnologia legada também definiu uma mentalidade que restringe o acesso mais eficiente aos dados, ou seja, uma mentalidade focada em projetos. A tecnologia e as práticas existentes forçaram as equipes de dados a criar novos pipelines para cada solicitação de dados. Essa abordagem reativa não considera as economias de escala proporcionadas pela construção de pipelines mais versáteis que podem ser usados e reutilizados.
Redefinindo a prática analítica
O setor está entrando em um novo estágio de desenvolvimento dominado pela automação, aprendizado de máquina (ML) e inteligência artificial (IA). O ritmo da tomada de decisões está acelerando, e a qualidade dos modelos de IA será um diferencial importante no mercado. Cientistas de dados precisam de acesso rápido a mais dados de alta qualidade para melhorar a precisão do modelo. Gerentes também precisam de acesso a dados contextuais ricos e de alta qualidade para acompanhar o ritmo das decisões impulsionadas pela automação e enfrentar os desafios que são muito complexos para a IA.
A tomada de decisão baseada em dados está se tornando um pré-requisito para ter sucesso em mercados competitivos, e as habilidades de engenharia de dados necessárias para dar suporte aos analistas são escassas. A IA se tornou popular, e aplicativos de alto impacto, como reconhecimento facial e ChatGPT, já estão ganhando força. Esses aplicativos são apenas a ponta do iceberg, pois os inovadores trabalham para integrar a IA à automação e aos processos de negócios.
As implicações da IA são amplas e impactantes, mas a confiabilidade desses modelos ainda é suspeita. Monitorar a IA e a automação, ao mesmo tempo em que garante que eles tenham acesso a dados de alta qualidade, será um diferencial importante na eficiência de condução. Aqueles que não conseguirem se adaptar rapidamente serão deixados para trás.
As empresas devem adotar uma nova abordagem de análise de dados para ter sucesso neste ambiente dinâmico. Este novo paradigma é centrado em quatro conceitos:
- Controle descentralizado e federação de dados
- Foco na colaboração e compartilhamento
- Foco em produtos de dados, não em projetos de dados
- Abraçando a inovação e a experimentação
Controle de Descentralização e Federação de Dados
Uma tecnologia de consulta poderosa projetada para um ambiente de nuvem distribuída está surgindo. Tecnologia de código aberto como a Trino, desenvolvida no Facebook, separa a função de computação do armazenamento para que cada uma possa ser dimensionada de forma independente. A tecnologia também divide o processo de consulta em etapas separadas. Essa arquitetura executa um pedaço de código conhecido como coordenador para gerenciar vários programas de trabalho que executam os processos de consulta de cada banco de dados separado. Essa tecnologia permite que uma única consulta extraia dados de várias fontes simultaneamente. Ela também permite o processamento paralelo para que grandes conjuntos de dados possam ser acessados muito mais rapidamente.
Com dados armazenados em vários bancos de dados acessíveis com uma única consulta SQL federada, a análise de dados se torna muito mais simples e rápida. Engenheiros de TI e dados não precisam criar pipelines ETL complexos para mover dados de uma fonte para um banco de dados de destino, que deve ser mesclado e transformado antes de poder ser preparado para análise. Os dados também permanecem em um só lugar, reduzindo a quantidade de dados replicados armazenados nos estados de TI e reduzindo custos e erros de armazenamento. Não consolide dados e adicione governança; deixe os dados onde estão e centralize a governança, os metadados e a capacidade de descoberta.
Metadados consolidados
Embora as consultas de dados federadas sejam ótimas para obter dados, elas não são tão boas para encontrá-los. Elas precisam de um mapa ou índice para encurtar o tempo necessário para localizar os dados apropriados. Esse desafio está levando à criação de mecanismos de descoberta inovadores. As estratégias de gerenciamento de metadados estão permitindo que as consultas federadas operem de forma muito mais eficiente. Ao consolidar metadados em um local central, os mecanismos de consulta federada podem determinar rapidamente onde encontrar dados sem escanear cada um dos seus bancos de dados distintos para cada consulta.
Metadados consolidados podem ser organizados em catálogos de dados, e conexões entre diferentes conjuntos de dados podem ser mapeadas usando gráficos de conhecimento. A indexação de metadados reduz drasticamente o tempo que uma consulta federada leva para ser executada.
Governança Descentralizada
Embora o software de código aberto seja ótimo, ele normalmente não está pronto para empresas. Para que as organizações tenham certeza de que os dados estão seguros, e os tomadores de decisão confiem que seus dados são precisos e completos, é necessária uma governança adequada.
Antes da implementação de estratégias de federação de dados, quando os dados eram centralizados e acessados por pipelines de dados ETL, a TI tinha que construir segurança e governança em cada pipeline. Com essas barreiras técnicas caindo, novas abordagens para governança são possíveis.
Uma camada de federação suportada por software de código aberto como o Trino permite mais controle onde a governança pode ser implementada de forma mais eficiente. O acesso não precisa ser controlado e gerenciado em cada sistema de origem individual, mas sim em uma camada centralizada. Com metadados detalhados centralizados, o acesso e a qualidade dos dados podem ser gerenciados de uma plataforma central em vez de na fonte de dados. Essa configuração permite muito mais eficiências e controles de acesso granulares. A centralização de dados via ETL leva à perda de contexto, e o rastreamento da linhagem se torna mais difícil. O acesso direto aos sistemas de origem torna a linhagem de dados muito mais direta.
Colaboração e Compartilhamento
A nova mudança na arquitetura de análise de dados permite compartilhamento e colaboração mais fáceis. Com metadados centralizados, entender dados e seu contexto se torna mais direto, tornando o compartilhamento seguro de dados entre domínios muito mais simples. O acesso pode ser definido no nível de dados em vez de no nível de tecnologia. Engenheiros de dados não precisam determinar quem tem acesso a qual sistema de origem e criar essa política em seu pipeline. Com metadados abstraídos dos dados de origem, o acesso pode ser definido no nível da tabela de dados, permitindo um compartilhamento de dados muito mais eficaz.
Com o compartilhamento de dados, a análise de dados se torna um esporte de equipe. A alfabetização de dados cresce, e o conhecimento de ciência de dados se torna uma habilidade essencial de qualquer tomador de decisão. Os cientistas de dados se tornaram menos divinos, pois mais do que eles fazem pode ser tratado por colegas mais alfabetizados em dados. Nem todos os funcionários podem ser cientistas de dados, mas entender os conceitos de ciência de dados está se tornando uma habilidade essencial.
Produtos de dados vs Projetos de dados
Empacotar dados em produtos de dados reutilizáveis oferece novas oportunidades neste novo paradigma. Com as ferramentas para acessar e governar dados disponíveis em um único lugar, a construção de produtos de dados reutilizáveis pode ser simplificada. Uma vez que tenhamos uma melhor compreensão de nossos dados por meio do gerenciamento de metadados consolidado, a construção de projetos de pipeline de dados pontuais que envolvam a busca por dados, sua compreensão e aplicação de governança de forma independente não é mais a única opção. Podemos começar a pensar em dados como um produto empacotado com governança e projetado para ser mais flexível e reutilizável. Os produtos de dados são construídos com dados integrados, limpos, normalizados e aumentados para fornecer o conjunto de dados de maior valor.
Com um controle de acesso mais granular, mais usuários podem acessar produtos de dados. Essa abordagem é uma mudança significativa do projeto de dados personalizados monolíticos inflexíveis, onde o acesso deve ser definido no nível do sistema de origem. Empacotar produtos de dados e publicá-los em um mercado os torna mais acessíveis e self-service.
Mudar para produtos de dados também torna a análise de dados mais proativa em vez de reativa. Em vez de responder a solicitações de dados, os gerentes podem antecipar quais produtos de dados podem ser necessários. Essa mudança torna a experiência em gerenciamento de produtos valiosa. Uma mentalidade que considera as necessidades futuras dos consumidores de dados e a melhor forma de entregar valor é uma característica que dará suporte a estratégias bem-sucedidas de produtos de dados.
Experimentação e Inovação
O novo paradigma de análise de dados inaugurará maior inovação e experimentação. Com metadados centralizados dando suporte a catálogos de dados globais que indexam dados em todo o seu patrimônio de TI, descobrir novos dados se torna muito mais simples. Analistas, engenheiros e gerentes de produtos de dados podem explorar novas fontes de dados para aprimorar suas análises ou produtos de dados. Com produtos de dados disponibilizados em um mercado, tomadores de decisão e cientistas de dados podem acessar conjuntos de dados com apenas alguns cliques do mouse. O grupo Eckerson - consultoria em análise de dados e grupo de pesquisa prevê que toda grande organização terá um mercado de produtos de dados em três a cinco anos.
A descoberta de novas fontes de dados e conjuntos de dados é a chave para maior experimentação e inovação. Catálogos de dados consolidados e mercados de produtos de dados tornam a descoberta muito mais fácil.
Novo paradigma na era da IA
A arquitetura de consulta em mudança cria oportunidades para alavancar a IA para maior eficiência e alcance. Os dados estão se tornando mais democratizados, pois qualquer pessoa com algumas habilidades em SQL e autoridade adequada pode alavancar um mecanismo de consulta federado para extrair dados de qualquer lugar da organização com um único script. Essa capacidade, combinada com a IA, está tornando os dados ainda mais self-service. Grandes modelos de linguagem podem ser usados para traduzir linguagem comercial comum em uma consulta SQL, eliminando a necessidade de saber SQL. A Gen AI também oferece suporte a análises aumentadas, onde os usuários comerciais podem pedir a um mecanismo de IA para conduzir análises para eles. Pergunte a um chatbot e a IA mostrará correlações entre conjuntos de dados ou identificará fatores que impulsionam tendências. Isso permite acesso de dados self-service ainda mais eficaz por analistas e tomadores de decisão não técnicos.
Novas capacidades
À medida que a IA se torna mais poderosa e as barreiras ao acesso aos dados desaparecem, os insights da IA serão alimentados diretamente no fluxo de trabalho de automação, resolvendo problemas diretamente sem intervenção humana. Embora isso pareça utópico, essa realidade pode estar aqui antes que percebamos. Os humanos terão que monitorar esses processos e verificar novamente a saída da IA. A capacidade de não apenas construir esses modelos, mas também monitorá-los, exigirá fácil acesso aos dados por humanos e uma compreensão de como esses modelos funcionam.
Solicite uma demonstração HOJE!
Take the leap from data to AI
