Der neue Plan für Analysepraktiken: Die Zukunft der Entscheidungsfindung gestalten
Das Verstehen von Informationen ist ein ewiges Streben des Menschen. Die Technologie zur Verwaltung von Daten hat sich weiterentwickelt, seit prähistorische Menschen begannen, die Wände ihrer Höhlen zu bemalen. Heute entwickelt sich die Technologie extrem schnell, da wir uns auf einen Paradigmenwechsel in der Art und Weise zubewegen, wie wir unsere Fortschritte nutzen, um Daten zu analysieren und die Entscheidungsfindung zu unterstützen.
Die Entwicklung der Datenanalysepraxis
Die digitale Speicherung und Übertragung von Daten hat sich rasant entwickelt. In den letzten Jahrzehnten hat die Technologie ihre Fähigkeit verbessert, immer größere Mengen und unterschiedliche Datenformen zu erfassen, zu speichern und zu verwalten.
BI und Data Warehouses
Die moderne Datenanalyse entstand mit der Entwicklung von Business-Intelligence-Anwendungen und Data Warehouses. In dieser Entwicklungsphase wurden Daten erfasst und in einer sehr strukturierten relationalen Datenbank gespeichert. Die Zuordnung zwischen Datentabellen war klar definiert, um einen einfachen Zugriff auf Business-Intelligence-Anwendungen zu ermöglichen. Das Ergebnis war, dass die Ergebnisse der Datenanalyse sehr beschreibend und diagnostisch waren. Anhand dieser Daten konnten Unternehmensleiter sehen und verstehen, was in der Vergangenheit in ihren Betrieben passiert war.
Big Data, Open Source und die Cloud
Die Skalierbarkeit der Cloud, die Datenerfassungsfähigkeiten mobiler und IoT-Geräte sowie die Innovationskraft von Open-Source-Technologien haben das Zeitalter von Big Data eingeläutet. Herkömmliche Data Warehouses und strukturierte Datenbanken konnten nicht skaliert werden, um die Anforderungen an die Unterbringung der ständig generierten riesigen Datenmengen zu erfüllen – von 2010 bis 2017 stieg die jährlich produzierte Datenmenge von 2 Zettabyte auf 26.
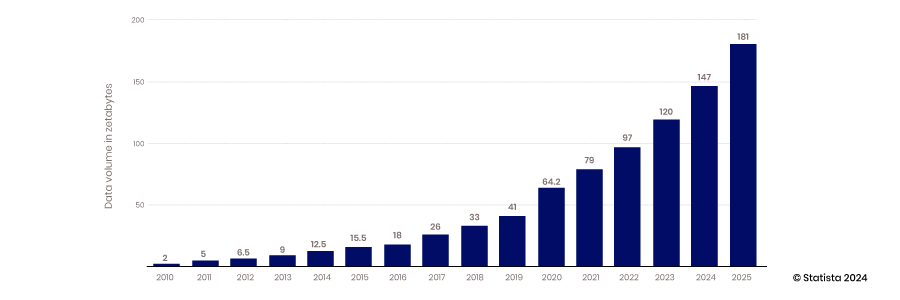
Die meisten der in diesem Zeitraum erstellten Daten waren unstrukturiert. Daher war es schwierig, sie in einer strukturierten relationalen Datenbank zu speichern. Um dieses Problem zu lösen, wurden Data Lakes erstellt, indem diese Daten in Flatfiles gespeichert wurden. Heute sind 80–90 % der Daten in Data Lakes unstrukturiert. Wenn all diese Daten gespeichert sind, besteht die nächste Herausforderung darin, auf sie zuzugreifen und sie zu verwenden.
Um dieses Problem anzugehen, entstand eine Community aus Analysten und Dateningenieuren, die die erforderlichen Fähigkeiten und Werkzeuge entwickelte, um die Leistungsfähigkeit der Daten zu nutzen. Diese Entwicklung umfasste Open-Source-Projekte und den Aufbau von Fähigkeiten zur Datentransformation und zur Entwicklung ausgefeilterer Analysetechniken. Zu diesem Trend gehörte auch die Einbeziehung von Metadaten, um einen leichteren Zugriff auf Daten in einer weniger organisierten Welt zu ermöglichen.
Durch den Zugriff auf mehr Daten sowie neue Fähigkeiten und Werkzeuge wurden die Analysen prädiktiver und es entstanden Modelle, die mehr Einblicke in zukünftige Ereignisse bieten konnten.
Datenwissenschaft und Datenanwendungen
Mit dem Wachstum der Datenerfassung und dem Aufbau von Datenanalysefähigkeiten verlagerte der Markt seinen Fokus auf die Frage, wie diese Fähigkeiten genutzt werden können, um Wettbewerbsvorteile zu erzielen. Die Kombination wissenschaftlicher Methoden mit Statistik, Algorithmenentwicklung und Systemwissen führte zur Entstehung der Datenwissenschaft. Diese Fähigkeit ermöglicht es Unternehmen, ihre Daten nicht nur zum Aufbau prädiktiver Modelle zu nutzen, sondern auch Systeme zu entwickeln, die die beste Alternative zu jeder Entscheidung vorgeben. Dieser Fortschritt führt zu mehr Automatisierung und Unternehmen werden agiler und reaktionsfähiger.
Die Technologie für Datenbewegung und -integration hält nicht Schritt
Die Datenerfassung, -speicherung und -analyse haben sich im Laufe der Jahre erheblich verändert, aber beim Zugriff auf und der Integration von Daten gab es kaum Fortschritte. Technologien und Ansätze wie ETL wurden vor der Cloud, Open-Source-Technologie und KI entwickelt.
Der Drang, die Möglichkeiten von Daten, Analysen und Datenwissenschaft zur schnellen Lösung realer Geschäftsprobleme einzusetzen, erfordert ein Umdenken hinsichtlich der effizienteren Datennutzung. Daten sind in Datenseen oder Geschäftsanwendungen gefangen und die Technologie zum Zusammenführen dieser Datensätze für eine tiefergehende Analyse hat nicht Schritt gehalten.
Technische Barrieren
Die Standardmethode zur Integration und zum Zugriff auf Daten hat sich seit dem Aufkommen von Data Warehouse und BI nicht geändert. SQL ist der Standard zum Abrufen von Daten aus Datenbanken, und ETL ist nach wie vor der Standardprozess zum Integrieren von Daten aus verschiedenen Systemen. Um auf diese Weise auf Daten zuzugreifen, müssen Benutzer SQL-Skripte zum Abfragen der Daten schreiben, wissen, wie die Daten organisiert sind, und verstehen, wie die Datenbanktechnologie funktioniert. Zum Zusammenführen von Datensätzen müssen ausgefeilte Prozesse erstellt werden, um Daten aus einem System zu extrahieren, zu transformieren und in eine andere Datenbank zu laden. Im Grunde haben sich diese Prozesse nicht geändert.
Politische Barrieren
Auch politische Hürden können den technischen Zugriff auf Daten erschweren. Diejenigen, die Daten sammeln und für sie verantwortlich sind, können den Zugriff einschränken. Wenn sie die Daten weitergeben, müssen diese Domäneninhaber überwachen, wie sie verwendet werden. Besonders besorgniserregend sind sensible Daten. Werden die Daten angemessen gespeichert, wenn sie weitergegeben werden? Werden die Daten mit dem gebotenen Respekt behandelt? Werden beispielsweise Analysten, die die Nuancen der HIPAA-Regeln nicht verstehen, gegen Richtlinien verstoßen, die das Unternehmen und seine Kunden gefährden?
Und werden Analysten in anderen Abteilungen die Bedeutung der Daten verstehen, die ihnen zur Verfügung gestellt werden? Werden sie die Daten im richtigen Kontext analysieren? Dies alles sind berechtigte Bedenken, die die Weitergabe in der aktuellen Umgebung einschränken.
Das jahrzehntelange Arbeiten mit veralteter Technologie hat zudem eine Denkweise geprägt, die einen effizienteren Datenzugriff einschränkt – nämlich eine projektorientierte Denkweise. Bestehende Technologien und Praktiken haben Datenteams gezwungen, für jede Datenanforderung neue Pipelines zu erstellen. Dieser reaktive Ansatz berücksichtigt nicht die Skaleneffekte, die durch den Aufbau vielseitigerer Pipelines erzielt werden, die verwendet und wiederverwendet werden können.
Neudefinition der Analytics-Praxis
Die Branche bewegt sich in eine neue Entwicklungsphase, die von Automatisierung, maschinellem Lernen (ML) und künstlicher Intelligenz (KI) dominiert wird. Das Tempo der Entscheidungsfindung nimmt zu und die Qualität der KI-Modelle wird ein entscheidendes Differenzierungsmerkmal auf dem Markt sein. Datenwissenschaftler benötigen schnellen Zugriff auf mehr qualitativ hochwertige Daten, um die Modellgenauigkeit zu verbessern. Manager benötigen außerdem Zugriff auf umfangreiche, qualitativ hochwertige, kontextbezogene Daten, um mit dem Tempo der durch Automatisierung bedingten Entscheidungen Schritt zu halten und die Herausforderungen zu bewältigen, die für KI zu komplex sind.
Datengestützte Entscheidungsfindung wird zur Voraussetzung für den Erfolg in wettbewerbsintensiven Märkten, und die zur Unterstützung von Analysten erforderlichen Datentechnikkenntnisse sind Mangelware. KI ist zum Mainstream geworden, und wirkungsvolle Anwendungen wie Gesichtserkennung und ChatGPT gewinnen bereits an Dynamik. Diese Anwendungen sind nur die Spitze des Eisbergs, während Innovatoren daran arbeiten, KI in Automatisierungs- und Geschäftsprozesse zu integrieren.
Die Auswirkungen der KI sind weitreichend und wirkungsvoll, aber die Zuverlässigkeit dieser Modelle ist noch immer fraglich. Die Überwachung von KI und Automatisierung bei gleichzeitiger Sicherstellung des Zugriffs auf qualitativ hochwertige Daten wird ein entscheidender Faktor für die Steigerung der Effizienz sein. Diejenigen, die sich nicht schnell anpassen können, werden abgehängt.
Um in diesem dynamischen Umfeld erfolgreich zu sein, müssen Unternehmen einen neuen Ansatz für die Datenanalyse verfolgen. Dieses neue Paradigma basiert auf vier Konzepten:
- Dezentrale Steuerung und Datenföderation
- Konzentrieren Sie sich auf Zusammenarbeit und Austausch
- Konzentrieren Sie sich auf Datenprodukte, nicht auf Datenprojekte
- Innovation und Experimentierfreude
Dezentralisierungskontrolle und Datenföderation
Es entstehen leistungsstarke Abfragetechnologien, die für eine verteilte Cloud-Umgebung entwickelt wurden. Open-Source-Technologien wie Trino, die bei Facebook entwickelt wurden, trennen die Rechenfunktion vom Speicher, sodass beide unabhängig voneinander skaliert werden können. Die Technologie zerlegt den Abfrageprozess außerdem in einzelne Schritte. Diese Architektur führt einen Codeabschnitt aus, der als Koordinator bezeichnet wird, um mehrere Arbeitsprogramme zu verwalten, die die Abfrageprozesse für jede einzelne Datenbank ausführen. Diese Technologie ermöglicht es einer einzelnen Abfrage, Daten gleichzeitig aus verschiedenen Quellen abzurufen. Sie ermöglicht auch die Parallelverarbeitung, sodass auf große Datensätze viel schneller zugegriffen werden kann.
Wenn Daten in mehreren Datenbanken gespeichert sind und mit einer einzigen föderierten SQL-Abfrage zugänglich sind, wird die Datenanalyse viel einfacher und schneller. IT- und Dateningenieure müssen keine komplexen ETL-Pipelines erstellen, um Daten von einer Quell- in eine Zieldatenbank zu verschieben, die zusammengeführt und transformiert werden müssen, bevor sie für die Analyse vorbereitet werden können. Die Daten bleiben außerdem an einem Ort, wodurch die Menge der in den IT-Umgebungen gespeicherten replizierten Daten reduziert und Speicherkosten und Fehler reduziert werden. Konsolidieren Sie keine Daten und fügen Sie keine Governance hinzu; lassen Sie die Daten dort, wo sie sind, und zentralisieren Sie Governance, Metadaten und Auffindbarkeit.
Konsolidierte Metadaten
Während föderierte Datenabfragen beim Abrufen von Daten hervorragend sind, sind sie beim Auffinden dieser Daten weniger gut. Sie benötigen eine Karte oder einen Index, um die zum Auffinden der entsprechenden Daten erforderliche Zeit zu verkürzen. Diese Herausforderung führt zur Entwicklung innovativer Erkennungsmechanismen. Strategien zur Metadatenverwaltung ermöglichen es, föderierte Abfragen viel effizienter auszuführen. Durch die Konsolidierung von Metadaten an einem zentralen Ort können föderierte Abfrage-Engines schnell ermitteln, wo Daten zu finden sind, ohne für jede Abfrage jede Ihrer unterschiedlichen Datenbanken durchsuchen zu müssen.
Konsolidierte Metadaten können in Datenkatalogen organisiert werden und Verbindungen zwischen verschiedenen Datensätzen können mithilfe von Wissensgraphen abgebildet werden. Durch die Indizierung von Metadaten lässt sich die Ausführungszeit einer föderierten Abfrage drastisch verkürzen.
Dezentrale Verwaltung
Open-Source-Software ist zwar großartig, aber in der Regel nicht unternehmenstauglich. Damit Unternehmen darauf vertrauen können, dass ihre Daten sicher sind, und damit Entscheidungsträger darauf vertrauen können, dass ihre Daten korrekt und vollständig sind, ist eine ordnungsgemäße Governance erforderlich.
Vor der Implementierung von Datenföderationsstrategien, als die Daten noch zentralisiert und über ETL-Datenpipelines abgerufen wurden, musste die IT in jede Pipeline Sicherheit und Governance integrieren. Mit dem Wegfall dieser technischen Barrieren sind neue Governance-Ansätze möglich.
Eine Föderationsschicht, die von Open-Source-Software wie Trino unterstützt wird, ermöglicht mehr Kontrolle, sodass Governance effizienter umgesetzt werden kann. Der Zugriff muss nicht auf jedem einzelnen Quellsystem kontrolliert und verwaltet werden, sondern auf einer zentralen Schicht. Durch die Zentralisierung detaillierter Metadaten können Zugriff und Datenqualität von einer zentralen Plattform aus verwaltet werden, anstatt von der Datenquelle aus. Diese Konfiguration ermöglicht viel mehr Effizienz und granulare Zugriffskontrollen. Die Zentralisierung von Daten über ETL führt zu Kontextverlust und die Nachverfolgung der Herkunft wird schwieriger. Der direkte Zugriff auf Quellsysteme macht die Datenherkunft viel einfacher.
Zusammenarbeit und Freigabe
Die neue Architektur der Datenanalyse ermöglicht einfacheres Teilen und Zusammenarbeiten. Durch die Zentralisierung der Metadaten wird das Verständnis der Daten und ihres Kontexts einfacher, was das sichere Teilen von Daten über Domänen hinweg wesentlich vereinfacht. Der Zugriff kann auf Datenebene statt auf Technologieebene definiert werden. Dateningenieure müssen nicht bestimmen, wer Zugriff auf welches Quellsystem hat, und diese Richtlinie in ihre Pipeline integrieren. Durch die Abstrahierung der Metadaten von den Quelldaten kann der Zugriff auf Datentabellenebene definiert werden, was ein viel effektiveres Teilen von Daten ermöglicht.
Durch das Teilen von Daten wird die Datenanalyse zu einem Mannschaftssport. Die Datenkompetenz wächst und Data-Science-Kenntnisse werden zu einer Kernkompetenz jedes Entscheidungsträgers. Data Scientists sind weniger gottähnlich geworden, da ein größerer Teil ihrer Arbeit von Kollegen erledigt werden kann, die sich besser mit Daten auskennen. Nicht alle Mitarbeiter sind Data Scientists, aber das Verständnis von Data-Science-Konzepten wird zu einer Kernkompetenz.
Datenprodukte vs. Datenprojekte
Das Verpacken von Daten in wiederverwendbare Datenprodukte bietet in diesem neuen Paradigma neue Möglichkeiten. Mit den an einem einzigen Ort verfügbaren Tools zum Zugriff auf und zur Verwaltung von Daten kann die Erstellung wiederverwendbarer Datenprodukte rationalisiert werden. Sobald wir durch konsolidiertes Metadatenmanagement ein besseres Verständnis unserer Daten haben, ist das Erstellen einmaliger Datenpipeline-Projekte, die das Suchen nach Daten, deren Verständnis und die unabhängige Anwendung von Governance beinhalten, nicht mehr die einzige Option. Wir können anfangen, Daten als ein mit Governance verpacktes Produkt zu betrachten, das flexibler und wiederverwendbarer gestaltet ist. Datenprodukte werden mit integrierten, bereinigten, normalisierten und erweiterten Daten erstellt, um den wertvollsten Datensatz zu liefern.
Durch eine detailliertere Zugriffskontrolle können mehr Benutzer auf Datenprodukte zugreifen. Dieser Ansatz stellt eine wesentliche Änderung gegenüber dem unflexiblen monolithischen benutzerdefinierten Datenprojekt dar, bei dem der Zugriff auf der Ebene des Quellsystems definiert werden muss. Durch das Verpacken und Veröffentlichen von Datenprodukten auf einem Marktplatz werden sie zugänglicher und selbstbedienbarer.
Durch die Umstellung auf Datenprodukte wird die Datenanalyse zudem proaktiver statt reaktiver. Anstatt auf Datenanfragen zu reagieren, können Manager voraussehen, welche Datenprodukte möglicherweise benötigt werden. Diese Umstellung macht Erfahrungen im Produktmanagement wertvoll. Eine Denkweise, die die zukünftigen Bedürfnisse der Datenkonsumenten berücksichtigt und weiß, wie man am besten Mehrwert liefert, ist eine Eigenschaft, die erfolgreiche Datenproduktstrategien unterstützt.
Experimentieren und Innovation
Das neue Datenanalyse-Paradigma wird mehr Innovation und Experimentierfreude mit sich bringen. Mit zentralisierten Metadaten, die globale Datenkataloge unterstützen, die Daten in Ihrem gesamten IT-Umfeld indizieren, wird das Entdecken neuer Daten viel einfacher. Analysten, Ingenieure und Datenproduktmanager können neue Datenquellen erkunden, um ihre Analysen oder Datenprodukte zu verbessern. Mit Datenprodukten, die auf einem Marktplatz verfügbar gemacht werden, können Entscheidungsträger und Datenwissenschaftler mit nur wenigen Mausklicks auf Datensätze zugreifen. Die Eckerson Group – eine Beratungs- und Forschungsgruppe für Datenanalyse – prognostiziert, dass in drei bis fünf Jahren jedes große Unternehmen über einen Marktplatz für Datenprodukte verfügen wird.
Die Auffindbarkeit neuer Datenquellen und Datensätze ist der Schlüssel zu mehr Experimenten und Innovationen. Konsolidierte Datenkataloge und Datenproduktmarktplätze machen die Auffindbarkeit wesentlich einfacher.
Neues Paradigma im Zeitalter der KI
Die sich ändernde Abfragearchitektur schafft Möglichkeiten, KI für mehr Effizienz und Reichweite zu nutzen. Daten werden zunehmend demokratisiert, da jeder mit SQL-Kenntnissen und der entsprechenden Autorität eine föderierte Abfrage-Engine nutzen kann, um mit einem einzigen Skript Daten von überall in der Organisation abzurufen. Diese Fähigkeit, kombiniert mit KI, macht Daten noch selbstbedienbarer. Große Sprachmodelle können verwendet werden, um gängige Geschäftssprache in eine SQL-Abfrage zu übersetzen, wodurch SQL-Kenntnisse überflüssig werden. Gen AI unterstützt auch erweiterte Analysen, bei denen Geschäftsbenutzer eine KI-Engine bitten können, Analysen für sie durchzuführen. Fragen Sie einen Chatbot, und die KI zeigt Korrelationen zwischen Datensätzen auf oder identifiziert Faktoren, die Trends vorantreiben. Dies ermöglicht einen noch effektiveren selbstbedienten Datenzugriff durch nicht-technische Analysten und Entscheidungsträger.
Neue Funktionen
Da KI immer leistungsfähiger wird und Hürden beim Datenzugriff verschwinden, werden KI-Erkenntnisse direkt in Automatisierungsabläufe einfließen und Probleme ohne menschliches Eingreifen lösen. Das klingt zwar utopisch, aber diese Realität könnte schneller da sein, als wir es merken. Menschen müssen diese Prozesse überwachen und die KI-Ausgaben überprüfen. Die Fähigkeit, diese Modelle nicht nur zu erstellen, sondern auch zu überwachen, erfordert einen einfachen Zugriff der Menschen auf Daten und ein Verständnis dafür, wie diese Modelle funktionieren.
Fordern Sie HEUTE eine Demo an!
Take the leap from data to AI
